万字长文 - Nature 综述系列 - 给生物学家的机器学习指南 4
万字长文 - Nature 综述系列 - 给生物学家的机器学习指南 1
万字长文 - Nature 综述系列 - 给生物学家的机器学习指南 2 (传统机器学习方法如何选择)
万字长文 - Nature 综述系列 - 给生物学家的机器学习指南 3 (人工神经网络)

生物应用的挑战
也许建模生物数据的最大挑战是生物数据的多样性。生物学家使用的数据包括基因和蛋白质序列、随时间变化的基因表达水平、进化树、显微图像、3D结构和互作网络等。我们在表2中总结了特定生物数据类型的一些最佳实践和重要注意事项。由于所遇到的数据类型的多样性,生物数据通常需要一些定制的解决方案来有效地处理它们,这使得很难推荐现成的工具,甚至是通用的机器学习指南来进行模型的选择,训练程序和测试数据将在很大程度上取决于人们想要回答的确切问题。然而,为了在生物学中成功地使用机器学习,需要考虑一些常见的问题,但也需要更广泛地考虑。
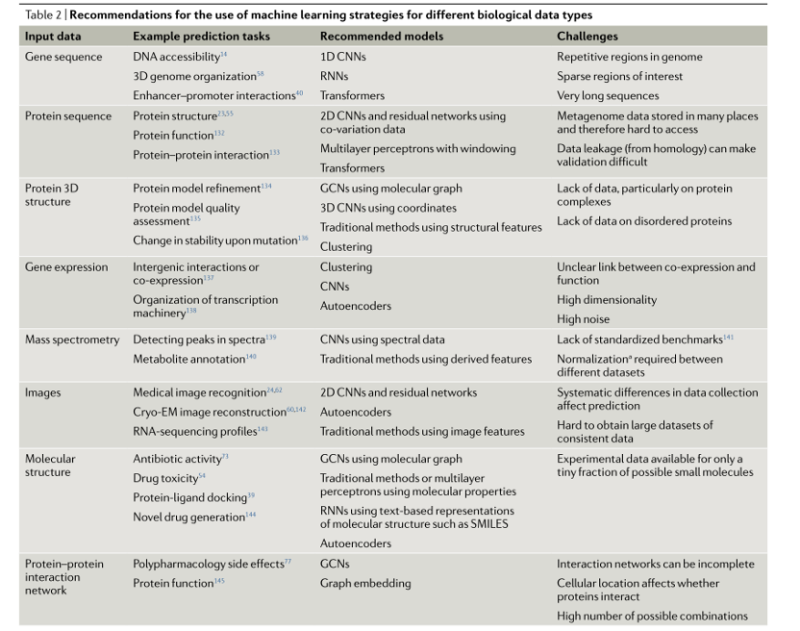
表2|针对不同生物数据类型使用机器学习策略的建议。上表列出每种类型生物数据的预测任务、适合的机器学习模型和相关的挑战。一些挑战,如维度灾难,影响大多数生物数据类型。CNN是卷积神经网络;cryo-EM是冷冻电子显微镜;GCN是图卷积网络;RNN是循环神经网络。’归一化’意味着重新缩放或以其他方式转换来自不同数据集的变量,以便这些变量的权重应大致平等,变量值的变化范围在一致空间上具有可比性。实现这一点的最常见方法是减去每个变量的均值并除以它们的标准差,这也可以称为’标准化’。这是必需的,因为不同的仪器、实验操作等可能导致对相同数量的测量产生系统差异,从而使得比较实验之间的趋势变得困难甚至不可能。
正则化:限制参数的取值范围以防止模型过拟合于训练数据。例如,在回归模型中惩罚高参数值可以降低模型的强试性(flexibility),并防止它对训练数据中的噪声进行拟合。
云计算:通过互联网提供的按需计算服务,包括计算能力和数据存储。通常采用按使用量付费的模式。使用云计算可以减少前期的IT基础设施成本。
隐马尔可夫模型:一种统计模型,可用于描述依赖于不可测量因素的可观测事件的演化。它在生物学中有多种用途,包括表示蛋白质序列家族。
显著性图:在机器学习的上下文中,显著性图指显示哪些像素对模型所做出的预测有贡献的可视化方式。它对解释模型非常有用。
自动微分:一组技术,用于自动计算计算机程序中函数的梯度。在训练神经网络时使用,其中被称为“反向传播(backpropagation)”。
梯度:一种属性随另一种属性变化的速率。在神经网络中,通过一种称为反向传播的过程计算损失函数相对于神经网络参数的一组梯度,用于调整参数训练模型。
数据可用性 。生物学在某种程度上是独特的,因为对于一些问题有大量公开可用的数据,而其他问题领域的数据量很小。例如,GenBank和UniProt等公共数据库中的生物序列数据相对丰富,而可靠的蛋白蛋白互作数据则更难获得。给定问题的可用数据数量对技术的选择有着深远的影响。作为一个非常粗略的指导原则,当只有少量数据(数百或数千个示例)可用时,人们基本上被迫使用更传统的机器学习方法,因为这些方法更有可能产生稳健的预测。当有更大的数据量可用时,可以开始考虑如深度神经网络这样的高度参数化的模型。在有监督的机器学习中,还应考虑数据集中有真实标签的数据的相对比例,如果某些数据真实标签很少,需要更多数据才能训练好机器学习模型。
数据泄漏。尽管生物数据的规模和复杂性可能使它们看起来非常适合机器学习,但仍有一些重要的考虑需要牢记。一个关键问题是如何验证模型的性能。常见的训练集、验证集和测试集的设定可能会导致一些问题,例如研究人员使用各种模型在同一测试集上重复测试,以获得最大的准确性,因此有可能在不推广到其他测试集或新数据的情况下高估模型的性能。然而,生物数据提出了一个更重要的问题:在具有相关条目的大型数据集中(例如,由于家族关系或进化关系),如何确保两个密切相关的条目不会最终一个分布于训练集一个分布于测试集?如果发生这种情况,那么测试的是模型记住特定案例的能力,而不是预测数据属性的能力。这是一个经常被称为“数据泄漏”的问题的一个例子,并导致结果看起来比实际情况更好,这可能是研究人员不愿对这个问题严格要求的原因之一。其他类型的数据泄漏也是可能的(例如,在训练期间使用数据或特征不应该在测试集出现)。在这里,我们关注的是在训练集和测试集中有关联样本的问题。
我们这里所说的“关联”取决于研究的性质。这可能是从同一患者或同一生物体中采集数据的情况。然而,生物学中发生数据泄漏的典型情况出现在对蛋白质序列和结构的研究中。通常,但这通常是不正确的,研究人员试图确保训练集中的任何蛋白质与测试集中的任何蛋白质的序列一致性都低于某一阈值,通常为30%或25%。这足以排除许多同源蛋白质对,但几十年来人们一直知道,一些同源蛋白质几乎没有序列相似性,这意味着仅仅通过序列同一性过滤不足以防止数据泄漏。这对于以序列比对或序列图谱作为输入的模型尤其重要,因为尽管两个单独的蛋白质序列可能没有任何明显的相似性,但它们的图谱可能实际上是相同的。这意味着对于一个机器学习模型,这两个图谱基本上是相同的数据点,它们都将描述相同的蛋白质家族。对于蛋白质序列,避免这一问题的一个解决方案是使用敏感的隐马尔可夫模型序列图谱比较工具(如HH-suite)对测试数据进行搜索找到并排除与训练集数据相关的序列。在蛋白质结构被用作输入或输出的常见情况下,可以使用CATH或ECOD等结构分类来排除类似的折叠或同源蛋白。类似的问题同样影响预测蛋白质-配体结合亲和力的研究。
显然,数据泄漏不是任何特定类型数据的固有问题,而是在训练和评估机器学习模型时如何使用数据的问题。人们肯定会期望经过训练的模型在与训练集类似的数据上产生非常好的结果。当在某个基准数据集上看起来准确的模型应用于与训练集不同的新数据上表现不佳时,数据泄漏问题就成了问题;换言之,该模型没有泛化,可能是因为它没有模拟变量之间的真实关系,而是记住了数据中存在的隐藏关联。
由于审稿人经常抱怨,一些期刊现在开始要求在考虑发表论文之前进行严格的基准测试。如果没有适当的测试,模型的性能很可能无法代表真实世界对未知数据的预测性能,这会削弱用户对模型的信心。更糟糕的是,未来研究的作者可能会被误导,认为不充分的测试是可以的,因为它已经出现在(可能是几篇)同行评审的文章中,尽管事实并非如此。如方框2所述,作者、同行评审员和期刊编辑都有责任确保避免数据泄露。明知故犯地将这些错误保留下来实际上不比编造数据好在哪。
Box 2 | evaluating articles that use machine learning
在阅读或审阅使用生物数据进行机器学习的文章时,这里有一些问题需要考虑。即使答案不明显,牢记这些考虑因素也是有益的,这些问题可以作为与具备所需专业知识的合作者进行讨论的基础。令人惊讶的是,许多文章并未满足这些标准。
1. 数据集描述是否充分?
应提供获取数据集的完整步骤,理想情况下,相关的数据集或数据概览(例如,生物数据库ID)应可在一个稳定的URL上获得。根据我们的经验,只对机器学习方法进行详尽描述,但对数据只进行简略引用,是一个警示信号。如果使用了标准数据集或来自其他研究的数据集,那么文章中应充分描述这一点。
2. 测试集是否有效?
根据“生物学应用的挑战”部分的讨论,检查测试集是否足以对所研究的问题进行基准测试。训练集和测试集之间不应有数据泄漏,测试集应足够大以提供可靠的结果,而且测试集应反映出该工具的标准用户可能使用的示例范围。训练集和测试集的组成和规模应详细讨论。作者有责任确保采取了所有措施避免数据泄漏,并且这些步骤应在文章中描述,同时附上这些操作的合理性描述。期刊编辑和同行评审人员也应确保这些任务已达到良好标准,当然不应只是假设已经完成这些任务。
3. 模型选择是否合理?
选择这一机器学习方法应给出理由。使用神经网络时是因为它们适用于当前的数据和问题,而不仅仅是因为其他人都在使用它们。应鼓励讨论尝试过但未能成功的模型,因为这可能会帮助他人;通常,一种复杂的模型被呈现出来时,很少会讨论实现该模型所需的不可避免的反复试验过程。
4. 该方法是否与其他方法进行了比较?
新方法应与已有的、在社区中被使用且表现良好的方法进行比较。理想情况下,应该比较采用各种模型类型的方法,这有助于解释结果。令人惊讶的是,许多复杂模型的性能可以被简单的回归方法所替代。
5. 结果是否好得令人难以置信?
在生物学领域的机器学习文章中,大于99%的准确率的声明并不罕见。通常,这是测试的问题而非惊人突破的表现。作者和审稿人都应注意这一点。
6. 该方法是否可用?
至少,希望从文章中使用一个已训练模型的人应该能够通过网络服务或二进制文件的方式运行预测。
理想情况下,至少源代码和训练过的模型应该在一个稳定的URL上公开可访问,并在一个通用许可下。
同时提供训练代码是更理想的情况,因为这将进一步提高文章的可重现性,并允许其他研究人员在方法的基础上进行构建,而无需从头开始。
期刊应对此承担一定的责任,以确保这成为常态。
模型的可解释性。生物学家通常想知道为什么某个特定的模型会做出特定的预测(也就是说,该模型对输入数据的哪些特征做出响应以及如何响应),以及为什么在某些情况下它会工作,但在其他情况下却不会。换言之,生物学家通常感兴趣的是发现建模的机制和影响模型的因素,而不仅仅是如前所述的精确建模。解释模型的能力取决于所使用的机器学习方法和输入数据。非神经网络方法的解释通常更容易,因为这些方法的特征集更易于直接有意义的解释,并且通常具有较少的可学习参数。例如,在简单线性回归模型的情况下,分配给每个输入特征的参数直接指示该特征如何影响预测。
训练非神经网络方法的低成本意味着进行消融实验 (ablation studies, 模型简化测试)是可取的,可以评估移除特定的特征对性能的影响。消融实验可以揭示哪些特征对当前的建模任务最有用,并且是可能发现更稳健、高效和可解释模型的一种方法。
由于模型中经常有大量的输入特征和参数,解释神经网络(特别是深度神经网络)通常要困难得多。例如,仍然可以通过构建显著性图来识别输入图像中对特定分类贡献最大的区域。虽然显著性图显示了图像的哪些区域是重要的,但要精确定位这些区域中数据的哪些特征对预测最重要更加困难,尤其是当输入信息不容易被人类理解时,例如图像和文本。然而,显著性图和类似的表示可以用作“合理性检查 (sanity check)”,以确保模型确实在查看图像的相关部分。这有助于避免模型构建意料之外的连接的情况,例如根据图像角落中的医院或科室标签而不是图像本身的医疗内容对医疗图像进行分类。生成对抗性示例,即导致神经网络产生可信的错误预测的合成输入,也可以评估哪些特征最常用于模型预测。例如,CNN通常使用纹理(如动物皮毛中的条纹)来对图像中的对象进行分类,而人类主要使用形状。
保护隐私的机器学习。一些生物数据,尤其是人类基因组学数据和商业敏感药物数据,具有数据隐私问题。在不侵犯数据隐私的情况下,已经做出了许多努力来允许数据共享和机器学习模型的分布式训练。例如,现代密码技术允许训练药物-靶点互作模型,其中数据和结果被证明是安全的。与临床试验中的真实参与者非常相似的模拟、合成参与者可以得出对真实参与者准确的结果,而不会泄露身份数据。已经开发了利用存储在不同位置的数据进行有效联合模型训练的算法。
跨学科合作的需要。除非使用公开可用的数据,否则很少有一个研究小组拥有专门知识和资源,既能为机器学习研究收集数据,又能有效应用最合适的机器学习方法。实验生物学家与计算机科学家合作是很常见的,这种合作通常会获得优异的结果。然而,在这样的合作中,重要的是双方都对对方的知识有一定的了解。特别是,计算机科学家应该努力了解数据,例如期望的噪声和数据重复性程度,生物学家应该了解所使用的机器学习算法的局限性。建立这样的理解需要时间和努力,但对于防止无意中传播糟糕的模型和误导性结果很重要。
未来方向
在可预见的未来,机器学习在生物研究中的应用越来越多。计算方法论、软件和硬件方面的重要进步推动了这一增长,所有这些都在不断发展。许多大型科技公司正在利用他们的技术专长和大量资源来帮助学术研究人员,甚至利用创新的机器学习策略进行自己的生物学研究。然而,迄今为止,大多数成功都来自于将其他领域开发的算法直接应用于生物数据。例如,CNN和RNN是分别为图像分析(用于人脸识别或自动驾驶汽车)和自然语言处理等应用开发的。生物学中机器学习最令人兴奋的前景之一是专门针对生物数据和生物问题的算法。如果可以利用生物系统的已知结构,并使用神经网络来学习未知部分,那么可以用更易于解释和对新数据更鲁棒的更简单的模型来代替重参数化模型。生物反应系统和药代动力学等应用可以使用已知微分方程系统。这也将有助于从预测模型转向生成模型,从而创建新的实体,例如设计具有新颖结构和功能的蛋白质。
随着各种有用的架构和输入数据类型的增加,可微分编程的范式正从深度学习领域兴起。可微分编程是使用自动微分(训练神经网络的中心概念)来计算梯度并改进任何期望算法中的参数。这在蛋白质结构预测系统中的物理模型以及在分子动力学模拟中的学习力场参数模拟方面很有应用前景。开发可微分的软件包(如JAX)和针对特定生物学领域(如Selene``、Janggu和JAX MD`)定制的软件包将有助于此类方法的开发。
利用机器学习进行生物数据分析的进展,也得益于将经过训练的模型存放在公开可用的存储库中。通过这种方式,研究类似问题的研究人员可以使用这些模型,而不需要再次训练,并且可以使用各种不同的模型,只在它们之间切换只需要很小的工作。另外还有自动机器学习流程的扩展,该流程在无需用户输入的情况下训练和调整各种模型,并返回性能最佳的模型。这些可以帮助非专家进行模型训练。然而,这些资源不能取代对所使用方法的彻底理解,这对于选择适当的归置偏差和解释模型的预测很重要。未来,自动化机器学习是否足够可靠和灵活,以允许实验者独立地常规使用复杂的机器学习算法,或者机器学习专业知识是否仍然是必要的,还有待观察。
正如已经讨论过的,严格验证模型和比较不同的模型具有挑战性,但仍有必要确定性能最佳的模型并为未来的研究方向提供信息。为了使该领域取得进展,有必要开发基准数据集和测试任务,如ProteinNet、ATOM3D和TAPE,并使其得到广泛应用。当然,对特定基准的过度优化可能会发生,重要的是研究人员要抵制住为使他们的结果看起来更好的诱惑。盲评估(如CASP和功能注释的关键评估)将继续在评估哪些模型表现最好方面发挥重要作用。
总的来说,生物数据的多样性使得很难为生物学中的机器学习提供一般指导。因此,我们在这里的目的是向生物学家概述可用的不同方法,并为他们提供如何利用数据进行有效的机器学习的一些想法。当然,机器学习并不适合每一个问题,知道何时避免它同样重要:当没有足够的数据时,当需要理解而不是预测时,或者当不清楚如何以公平的方式评估性能时。机器学习在生物学中何时有用的界限仍在探索中,并将根据可用实验数据的性质和数量不断变化。但不可否认,机器学习已经对生物学产生了巨大影响,并将继续如此。
大家都在看
-

大罗谈生涯最凶残被铲:对方鞋钉长到像穿高跟鞋,走路像机械战警 直播吧3月27日讯 大罗接受采访谈到职业生涯遭遇的恐怖经历,在那场比赛他遭遇一次暴力铲球,对方球鞋鞋钉巨长宛如“高跟鞋”,大罗描述对手走路姿势为“机械战警”。大罗:“我见过的最狠毒铲球之一就是这次。那天在 ... 机械之最03-28
-

燕山大学的王牌专业——机械工程,中等生的不二之选 我是两江综笃,在教育行业奋斗二十多年,对专业、院校的填报有自己的见解。关注我不迷路。 以下是正文:一、专业概况:底蕴深厚的行业标杆1.1 历史沿革与学科地位燕山大学机械工程学院的历史最早可追溯到 1958 年, ... 机械之最03-27
-

尼康相机创造过哪些“世界之最”?——众通社影像 【众通社影像按】第一、第一台最 “长寿” 的相机系统:F 卡口(64 年不退役)1959 年,尼康 F 卡口随初代单反 Nikon F 诞生,其内径 44mm、法兰距 46.5mm 的规格,在当时被视为 “过度设计”。但正是这份前瞻性,让 ... 机械之最03-23
-

各类轴体,75~98键,哪种机械键盘更适合你?自用百元键盘推荐 本内容来源于@什么值得买APP,观点仅代表作者本人 |作者:亦心之心我大概是从2023年开始,入了机械键盘的坑。零零总总入了不少机械键盘。这些键盘有些是三模的,有些是单模的,不同的轴体,不同的灯光效果,不同的 ... 机械之最03-22
-

哪个品牌机械手表最耐用 手表耐用与否跟手表的功能和手表佩戴人有关,再坚固的手表,像我之前写的一篇文章介绍的暴发户一样,把劳力士放火锅煮,也是不耐用的,所以不能笼统说哪个品牌耐用不耐用,但从总体上分析,以下这些是耐用的机械手表 ... 机械之最03-18
-

机械之美,齿轮运转,动力无限! 发明差速器的人真是太伟大了,因为没有差速器,所有的汽车将无法实现安全的转弯。当汽车转弯时,内侧车轮路径比外侧车轮路径短,因此外侧车轮必须在相同的时间内走比内侧车轮更长的距离,这意味着外侧车轮需要转的更 ... 机械之最03-13
-

标题:《探秘世界“巨无霸机械”:工业奇迹的力量与震撼》 正文:在人类科技发展的长河中,那些体型巨大、功能强大的“巨无霸机械”宛如工业文明的璀璨明珠,它们以令人惊叹的规模和卓越的性能,改变着我们的世界。今天,就让我们一同走进这些机械巨兽的世界,感受它们带来的 ... 机械之最03-13
-

学机械,这9所大学重点考虑! 机械工程专业涵盖机械设计、制造、自动化等领域,培养具备创新思维与实践能力的高素质人才,为现代工业发展奠定坚实基础。机械类专业被誉为国民经济的“装备部”,是我国高校开设最久的专业之一。什么样的学生适合学 ... 机械之最03-13
-

-

机械魅力:解锁机械结构设计的艺术之美✨ 【设计之美,匠心独运】探索机械结构设计的美学边界,每一幅线稿都是工程师与艺术家的灵魂碰撞。从精密的齿轮咬合到流畅的连杆运动,线条间流露出严谨与灵动的完美融合。本篇带你领略那些隐藏在日常背后的机械之美, ... 机械之最03-06
相关文章
- 钢铁丛林中的机械美学狂想曲
- 机械专业最具潜力的六个岗位,前景好,薪资高
- 为啥好多网友说乾隆就是一台冰冷的政治机器?网友回答道出真相
- 祖冲之:古代中国的数学巨匠与科学先驱
- “机械,最好找工作的专业之一”,山东二本,4个机械男,毕业8年
- 太重1300吨桥式起重机荣获2024年重型机械世界之最科技成果
- 又一项世界之最→太重集团1300t桥式起重机
- 又一殊荣 太重1300t桥式起重机荣获2024年重型机械世界之最科技成果
- 全省唯一!“洛阳制造”再添世界之最
- 经开快讯丨中国重型院项目荣获2024年重型机械世界之最科技成果
- 经开区企业快讯丨中国重型院项目荣获2024年重型机械世界之最科技成果
- 中信再添一“世界之最”中国造“世界最大球团回转窑”获官方认定
- 英国工程师:中国最让我“心塞”的,就是把顶尖机械卖成白菜价!
- 闻香识豆:科学如何赋予罗布斯塔咖啡豆新魅力
- 大国重器,3款世界最大机械,中国制造不输德国
- 盘点工程机械创造的,十大世界吉尼斯纪录!
- 中国农机化之最(四)
- 中国农机化之最(五)
- 机械键盘什么轴最好用?这篇文章告诉你
- 机械类最吃香的十大专业,未来绝对可以和计算机相抗衡的王牌







