SXM 与 PCIe:最适合训练 LLM 的 GPU,如 GPT-4
什么是 NLP,什么是 LLM?
自然语言处理(NLP)是人工智能(AI)的一个分支,使机器能够理解和解释人类语言。深度学习的最新进展导致了大型语言模型(LLM)的出现,它显示了不可思议的自然语言理解能力,彻底改变了世界,对未来产生了重大影响。初创企业和公司已经选择在 NVIDIA 的专用硬件上训练这些 LLMs:DGX。
大型语言模型(LLM)是一种语言模型,由在大量无标签文本数据上训练的参数神经网络组成。最著名的 LLM 是 OpenAI 的 GPT(Generative Pre-trained Transformer)系列,它已经在数十亿字的基础上进行了训练,是 ChatGPT 的基础。各种应用以 GPT 为基础,建立了极具说服力的聊天机器人、总结器等。LLM 在广泛的 NLP 任务中表现出卓越的性能,如语言翻译、问题回答和文本生成。ChatGPT(最初在 GPT-3 上训练)和 ChatGPT Plus(在 GPT-4 上训练)在将人工智能带到公众和消费者的关注点上掀起了巨大的波澜。
使我们的计算机能够与我们的物理世界互动已经成为现实。LLMs 在各个行业都有大量的应用,如个性化的聊天机器人、客户服务自动化、情感分析和内容创作,甚至是代码。那么,为什么这些大型组织会选择 NVIDIA DGX?DGX 和传统的 PCIe GPU 之间有什么区别?
NVIDIA DGX/HGX 和 SXM GPU 外形尺寸
SXM 架构是一种高带宽插座式解决方案,用于将 NVIDIA Tensor Core 加速器连接到其专有的 DGX 和 HGX 系统。对于每一代 NVIDIA Tensor Core GPU(P100、V100、A800 以及现在的 H800),DGX 系统 HGX 板都配有 SXM 插座类型,为其匹配的 GPU 子卡实现了高带宽、电力输送等功能。
专门的 HGX 系统板通过 NVLink 将 8 个 GPU 互连起来,实现了 GPU 之间的高带宽。NVLink 的功能使 GPU 之间的数据流动速度极快,使它们能够像单个 GPU 野兽一样运行,无需通过 PCIe 或需要与 CPU 通信来交换数据。NVIDIA DGX H100 连接了 8 个 SXM5 H800,通过 4 个 NVLink 交换芯片,每个 GPU的带宽为 400 GB/s,总双向带宽超过 3.2 TB/s。每个 H100 SXM GPU 也通过 PCI Express 连接到 CPU,因此 8 个 GPU 中的任何一个计算的数据都可以转发回 CPU。我们将在后面介绍架构原理图。

英伟达 H100 PCIe 外形尺寸
你无法通过 H100 PCIe 配备的 NVLink Bridges 与 PCIe 变体实现同样的性能带宽连接。这些桥接器只能将 GPU 成对连接在一起,实现 400GB/s 的双向传输,而不是通过系统中的 8 个 GPU 实现完整的 400GB/s。
现在不要误解,NVIDIA H100 PCIe 是一个非常有能力的 GPU,可以轻松部署。它们可以很容易地被安装到重视升级的数据中心中,只需最小的架构变化。H100 NVL 扩展了强大的 PCIe 卡,将它们搭配在一起,总共有 188GB HBM3,具有与 H100 SXM5 相当的性能。
我们的系统经过了严格的测试和验证。探索 联泰集群 Hooper H100 解决方案,包括 SXM 和 PCIe 选项!
H100 SXM 和 PCIE 的区别
众所周知,在数据中心和人工智能行业,NVIDIA DGX 简直就是黄金。它是最好的,也是最强大的 AI 机器。最突出的就是 OpenAI 在其 NVIDIA DGX 系统上训练 ChatGPT。事实上,OpenAI 早在 2016 年就拿到了第一台 NVIDIA DGX-1。
大型企业对英伟达 DGX 趋之若鹜,并不是因为它很耀眼,而是因为它的扩展能力。SXM GPU 更适合规模化部署,八 个 H100 GPU 通过 NVLink 和 NVSwitch 互连技术完全互连。在 DGX 和 HGX 中,8 个 SXM GPU 的连接方式与 PCIe 不同;每个 GPU 与 4 个 NVLink Switch 芯片相连,基本上使所有的 GPU 作为一个大 GPU 运行。这种可扩展性可以通过英伟达 NVLink Switch 系统进一步扩展,以部署和连接 256 个 DGX H800,创建一个 GPU 加速的 AI 工厂。
另一方面,H100 NVL 中的 H100 PCIe,只有成对的 GPU 通过 NVLink Bridge 连接。GPU 1 只直接连接到 GPU 2,GPU 3 只直接连接到 GPU 4,等等。GPU 1 和 GPU 8 没有直接连接,因此只能通过 PCIe 通道进行数据通信,不得不利用 CPU 资源。英伟达 DGX 和 HGX 系统板上的所有 SXM GPU 都通过 NVLink Switch 芯片互联,因此在 GPU 之间交换数据时不会因为 PCIe 总线的限制而减慢速度。向 CPU 发送数据仍将通过 PCIe 通道进行。
通过在 GPU 之间交换数据时绕过 PCI Express 通道,速度极快的 SXM H100 GPU 可以实现最大的吞吐量,而且比其 PCIe 同行的速度更慢,非常适合用于训练有海量数据的极大型AI模型。电力的消耗和专有的外形尺寸是对峰值性能的权衡,可以延长训练和推理时间。但是,当涉及到开发大型语言模型,对使用你的服务的数百万人进行文本推断时,需要最高形式的计算,以确保稳定性、流畅性和可靠性。
你应该选择什么?H100 SXM 还是 H100 PCIe?
这要看你的用例了。大型语言模型和生成性人工智能需要非常高的性能。但是,用户数量、工作负荷和训练规模在挑选合适的系统方面起着很大作用。
英伟达 H100 的 DGX 和 HGX 最适合那些能够利用原始计算性能的组织,不会让任何东西浪费掉。在发挥其最大潜力的情况下,不断的训练、推理和操作可以迅速降低总拥有成本。
NVIDIA DGX 具有最佳的可扩展性,所提供的性能是任何其他服务器在其给定的外形尺寸中无法比拟的。将多个 NVIDIA DGX H100 与 NVSwitch 系统连接起来,可以将多个 DGX H100 扩展为 SuperPod,以实现极大型模型。NVIDIA DGX H100 的外形尺寸为 8U,配备双英特尔至强8480C,共 112 个CPU核心。NVIDIA DGX 是不可定制的,是全面人工智能计算基础设施的构建模块。有了 NVIDIA DGX,在训练 LLM 时可以轻松地进行扩展。更多的 DGX 相当于更快的训练和更强大的部署。
英伟达 HGX 在单一系统中提供了强大的 GPU 性能,为用户提供了定制的选择。HGX 平台是由特定的合作伙伴(如 联泰集群)提供的可定制平台,可提供客户所需的性能-- CPU、内存、存储、网络--同时仍然利用相同的 8x NVIDIA H100 SXM5 系统板(包括所有 NVLink 的好处)。这些系统可以满足数据中心的需求,可以选择自己的网卡、自己想要的 CPU 核心数量,有时还可以选择额外的存储。英伟达 HGX 在计算能力方面与 DGX 类似,同时还能满足大规模 LLM 训练的需要。
英伟达 H100 PCIe 变体适用于那些工作负荷较小、希望在决定系统中的 GPU 数量方面获得最大灵活性的用户。在性能方面,这些 GPU 仍然很强大。它的原始性能数字略低,但由于易于安装到任何计算基础设施中,因此这些 GPU 非常引人注目。H100 PCIe 还提供较小的外形尺寸,如 1U 和 2U,供数据中心在单 CPU 或双 CPU 配置中使用 2x 或 4x GPU,为小型 LLM 开发提供计算能力。更多的 1 :1 的 CPU 与 GPU 比例有利于在推理中部署更多的虚拟化功能,以及分析等一系列不同的应用。

A100\H100在中国大陆基本上越来越少,A800目前也在位H800让路,如果确实需要A100\A800\H100\H800GPU,建议就不用挑剔了,HGX 和 PCIE 版对大部分使用者来说区别不是很大,有货就可以下手了。
无论如何,选择正规品牌厂商合作,在目前供需失衡不正常的市场情况下,市面大部分商家是无法供应的,甚至提供不属实的信息,如果是科研服务器的话首选风虎云龙科研服务器,入围政采,品质和售后服务都有保障。
欢迎交流 陈经理【173-1639-1579】
整理了一些深度学习,人工智能方面的资料,可以看看
一文看懂英伟达A100、A800、H100、H800各个版本有什么区别? - 知乎 (zhihu.com)
机器学习、深度学习和强化学习的关系和区别是什么? - 知乎 (zhihu.com)
人工智能 (Artificial Intelligence, AI)主要应用领域和三种形态:弱人工智能、强人工智能和超级人工智能。
买硬件服务器划算还是租云服务器划算? - 知乎 (zhihu.com)
深度学习机器学习知识点全面总结 - 知乎 (zhihu.com)
自学机器学习、深度学习、人工智能的网站看这里 - 知乎 (zhihu.com)
2023年深度学习GPU服务器配置推荐参考(3) - 知乎 (zhihu.com)
多年来一直专注于科学计算服务器,入围政采平台,H100、A100、H800、A800、RTX6000 Ada,单台双路192核心服务器有售,
机器学习:一切通过优化方法挖掘数据中规律的学科。
深度学习:一切运用了神经网络作为参数结构进行优化的机器学习算法。
监督学习、无监督学习和强化学习分别是机器学习中三个重要的课题。
强化学习:不仅能利用现有数据,还可以通过对环境的探索获得新数据,并利用新数据循环往复地更新迭代现有模型的机器学习算法。学习是为了更好地对环境进行探索,而探索是为了获取数据进行更好的学习。
可以学习和模拟人类的人工智能通常是由深度学习+强化学习实现的。 在算法方面,人工智能最重要的算法仍是神经网络。
多年来一直专注于科学计算服务器,入围政采平台,H100、A100、H800、A800、RTX6000 Ada,单台双路192核心服务器有售。
大家都在看
-
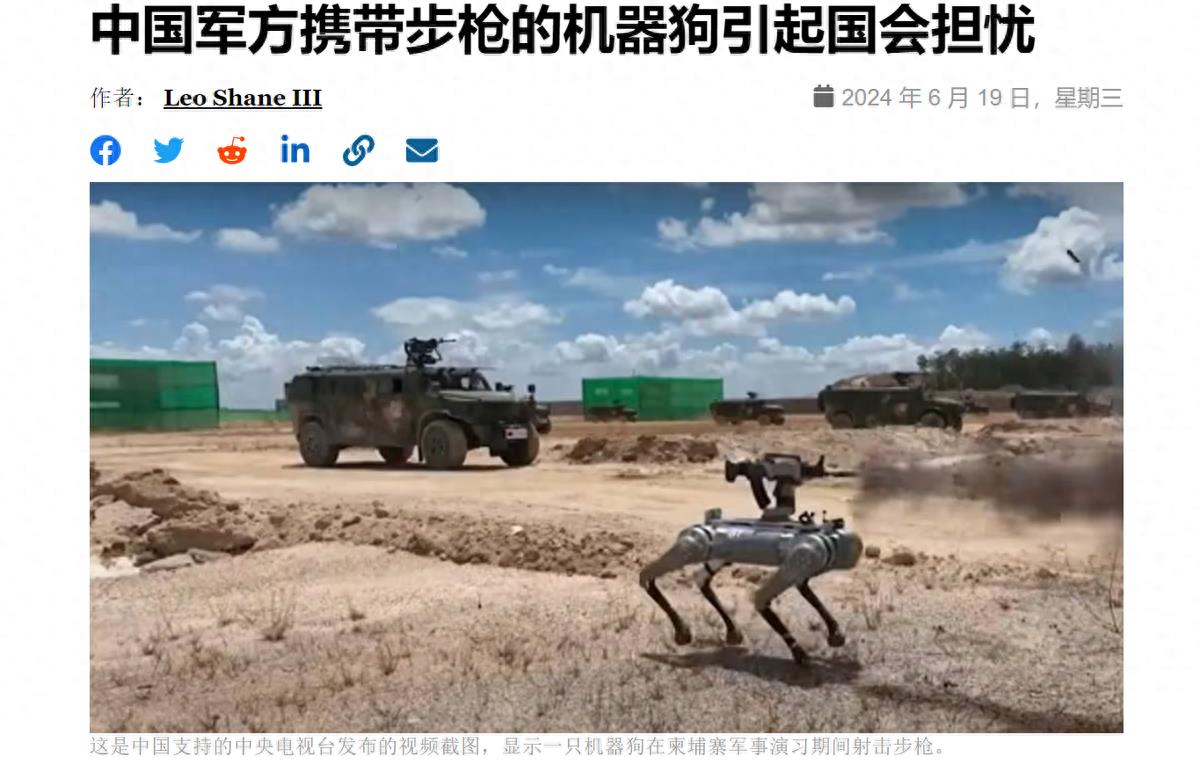
武装机器狗让美国国会紧张!工业生产能力太 【军武次位面】作者:路芷中国的狗为何能引起美国的广泛关注?甚至引起了美国国会的担忧。在上周美国举行的年度国防授权法案辩论中,美国众议院议员要求国防部对未来潜在的冲突当中中 机械之最07-04
-

环球视角:机器宠物风靡美国,可对抗“孤独 【环球网科技综合报道】7月1日,据科技媒体techcrunch报道,在“孤独流行病”日益严重的今天,机器猫、机器狗和机器鸟等高科技宠物正在成为美国老年人的新伙伴。这些可爱的机器人不仅 机械之最07-02
-

Solidworks设计学习打卡! 努力的人最帅! Solidworks新班学习。·中心到这个地方变成六点七,打勾,然后点一下确定。·大家可以看到这个地方是不是有个螺纹孔,螺纹孔就在这个地方生成的。·然后看一下侧面这个孔是不是在这里 机械之最06-30
-

中国空间站机械臂有多牛?舱外爬行、捕获飞 2017年10月,一枚神秘的太空拾取球正被社交媒体频繁分享着。这也是为数不多几次,我国的太空装备被公开展示。其实不难看出,它其实是我国那颗不甘在太空拾拾闲置的“大手”,非常像机 机械之最06-27
-

这就是顶级打工人戴表的天花板吗?一次性上 爱表这件事对我来说,最大的乐趣无非就是表友私下小聚,或者相约一起逛表店。前者可以让我有机会“沾染”一下别人的爱表,后者却让我不断获得一些体验。比如有些表很贵,我也很喜欢, 机械之最06-27
-

全球工程机械巨头风云榜:2024年度TOP 50深 在科技飞速发展的今天,工程机械行业正成为推动全球基础设施建设和经济发展的重要力量。近日备受瞩目的英国KHL集团旗下《国际建设》杂志发布了2024年度全球工程机械制造商50强排行榜( 机械之最06-24
-

你能忍受它的噪音吗,办公室到底该不该禁用 在现代办公环境中,机械键盘的使用一直存在争议。一方面,机械键盘手感出色、反馈明确,有助于提高工作效率;另一方面,其产生的噪音也可能影响到周围同事,降低工作环境的舒适度。这 机械之最06-21
-

“一招拆掉美国卫星”!空间站机械臂有多牛 文|大翠编辑|大翠前言:前段时间,“天宫TV”发布了一组空间站机械臂俯瞰地球的绝美照片,画面中的机械臂轻轻一抬手臂,仿佛在向地球招手,霸气侧漏的模样让无数网友为之惊叹。原来, 机械之最06-17
-

他是韩国最引以为豪的传奇人物,以一人之力 在不久的未来,因气候问题海平面上升和资源枯竭,人类为了生存决定迁移到太空,并成功在地月轨道间建造了适合人类居住的庇护所。但没过多久,有些庇护所擅自宣布独立,并成立了阿德里 机械之最06-17
-

机械性能检测中的最大力伸长率 机械性能检测是工程材料研究领域的重要一环,在评估材料的可靠性和耐久性时,最大力伸长率(elongation at maximum force)是-个重要的性能参数。本文将深入探讨最大力伸长率的定义及其 机械之最06-17
相关文章
- 机械性能检测中的最大力伸长率
- 6月以来已有477家上市公司获机构调研 工业
- 从汗水到智慧!记者蹲点调查新型工业化“临
- 全球十大机械巅峰之作
- 潍坊临朐:以奋斗之姿蓄能发展之势
- 机械男——齿轮知识之齿轮种类(一)
- 机械结构设计有什么最经典的资料?
- 纯粹的机械原理才是最安全的
- 热处理知识之金属材料的机械性能
- 机械键盘都卷什么?视觉、听觉、触觉三重体
- 北京月季文化节11个展区达历届数量之最,“
- 工程机械争霸战:徐州、长沙、柳州谁最强?
- 向新发力 向智图强 “起重机械之都”的长
- 对于结构机械工程师来说,哪个行业最赚钱?
- 工程机械 8种钢铁巨兽,你见过几个#机械设
- 徐州,长沙,柳州,谁是工程机械最强市?常
- 机械降神不止扫地僧,此人只出场一次,比神
- 问题:钢丝绳是起重机械应用最广泛的挠性构
- 工程机械,谁是盈利最强企业?
- 机械类专业大学排名 机械专业大学排名(全
热门阅读
-
 1
世界上最快的改装车:音速之风陆地极速车, 12-09
1
世界上最快的改装车:音速之风陆地极速车, 12-09 -
 2
天下第一暗器暴雨梨花针,传说中的唐门暗器 07-13
2
天下第一暗器暴雨梨花针,传说中的唐门暗器 07-13 -
 3
世界上最快的公交车:迪拜超级巴士,时速超 12-09
3
世界上最快的公交车:迪拜超级巴士,时速超 12-09 -
 4
4
-
 5
世界十大大型船舶排名,第一能承重六十万吨 07-13
5
世界十大大型船舶排名,第一能承重六十万吨 07-13 -
 6
世界上最早的自动枪,马克沁重机枪最高射速 11-20
6
世界上最早的自动枪,马克沁重机枪最高射速 11-20 -
 7
世界上寿命最短的大型航空母舰,短短的17个 04-26
7
世界上寿命最短的大型航空母舰,短短的17个 04-26 -
 8
美国枪店购买的百年名枪M1911 陨石制作一把 04-26
8
美国枪店购买的百年名枪M1911 陨石制作一把 04-26