构建实时机器学习管道的挑战
实时机器学习正在兴起,随着公司开始将实时引入他们的机器学习管道,他们发现自己不得不权衡性能、成本和基础设施复杂性之间的权衡,并确定哪些是优先考虑的。
在这篇文章中,我们将看看在从批处理到实时过渡的每个阶段发生的一些最典型的权衡,以及为什么这些优势和劣势是必须牢记的。
实时机器学习的典型路径
批量处理在数据不经常变化的情况下是最有用的,这在现在是很罕见的。它曾经被认为是采用机器学习的一种较低成本的方法,但许多使用批处理的公司开始意识到,对于那些不是每天都访问他们网站的用户的相关数据,在计算和存储上浪费了很多钱,所以预先计算的特征(他们预先花钱计算,现在又花钱存储)没有被查阅。这些公司正朝着实施实时机器学习的方向发展,尽管每一个计算单位对于实时来说都是比较昂贵的,因为这往往可以通过加快迭代周期,让他们只使用和存储相关的数据来节省资金。这种潜在的成本降低只会使公司在使用更多的最新数据时看到的模型性能优势更加突出,并能更快地对市场或用户偏好的变化做出反应。
如果你想进一步了解实时机器学习的优点,请查看我们的博文,内容是7个理由说明为什么实时机器学习会在这里继续存在.
第一阶段:所有都是批处理
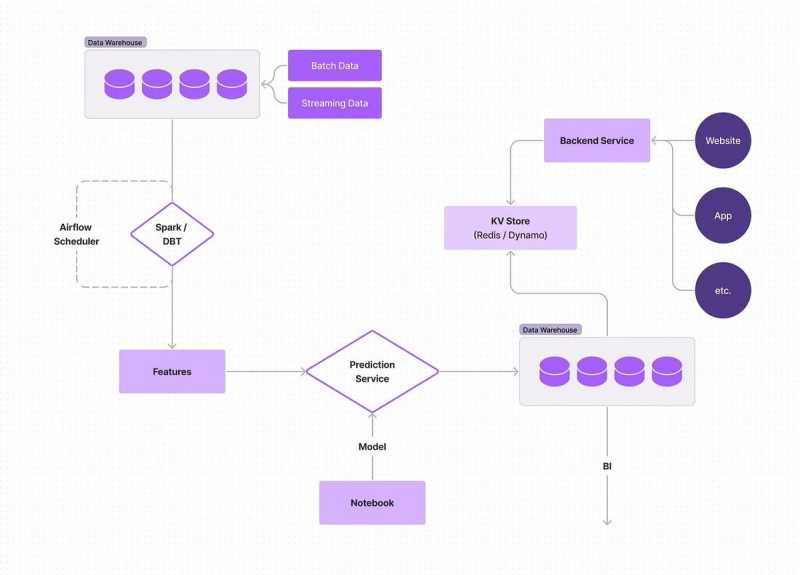
全批处理的实时机器管道是构建实时机器管道最常见的方法。在这种情况下,特征从一个批处理源计算,如Snowflake或S3,模型预测为每个用户/场景提前计算,存储,并在需要时提供。在某些情况下,模型预测甚至不在线提供(例如通过Redis);在这些情况下,一个批处理作业读取所有的模型分数并执行一个动作或计算(例如,如果模型预测用户是否会流失,一个管道读取这些分数并决定向他们发送电子邮件,所有这些都是离线发生的)。
批量机器学习管道的最大优势是,它相对容易设置,不需要实时数据。然而,缺点是批处理管道可能是缓慢和低效的,使它们不太适合大规模或时间敏感的数据。
挑战
所有批处理机器学习管道的最大挑战之一是陈旧的预测和开发一个修复它们的过程,或任何其他问题。因为数据被存储在一个静态的地方,你需要在训练前获取和处理数据。这个过程变得很乏味,因为任何时候你需要进行更新,无论多小的更新,你都需要再次经历获取、处理和训练的整个过程。在大多数情况下,这意味着许多采用批处理的公司并没有频繁地训练他们的模型,使其真正有用(因为他们不是最新的)。
另一个原因是,批处理程序需要巨大的数据集来保存所有的数据,因为你是为所有的用户(甚至只是所有的活跃用户)计算,而且没有任何个性化。这在一些特定的、简单的情况下可以起作用,但在我们目前的快节奏、高动态的世界中,对大多数情况并没有用。此外,在改变你的数据方面缺乏灵活性和速度,这对任何新用户的个性化都是一种挑战;第一印象对创造重复用户和减少用户流失是非常重要的,所以这种无法对新用户进行适当的个性化的情况会对企业产生重大影响。
上述的挑战也导致了实验速度的明显延迟。对于大多数公司经历的前三个阶段,模型的训练是有间隔的,但相对而言,批处理的间隔要长得多,因为你是在用静态的数据和模型工作,所以每次你给它提供新的数据时,要确定你的模型是在改进还是在漂移,这是非常耗时的。
阶段2:用实时模型批量计算的特征
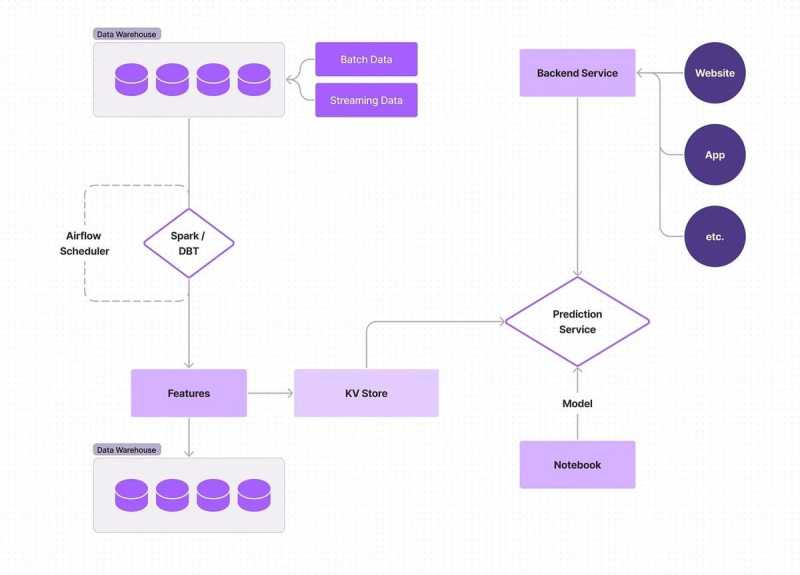
当公司开始将实时性整合到他们的机器学习管道中时,他们通常开始继续使用批量特征,但让模型实时使用批量计算的特征;模型实时提供服务,但计算的特征是在一个键值存储中。通过这种实现方式,你可以得到熟悉的静态数据的轻松和简单,但开始看到更多最新的模型和预测的一些准确性和性能优势。
挑战
随着特征被批量计算,你仍然必须确保你没有使用陈旧的特征,并且需要间隔训练模型,但这些间隔可以比所有批处理过程更短,因为你的反馈回路更短。既然如此,你现在必须注意你的模型服务,因为这是唯一的服务部分,所以它必须是可靠的,并有良好的服务水平协议。
如果不增加工作,你也不能完全获得实时的好处,因为你的功能仍然是静态的;即使你的模型是实时提供的,也需要大量的工作才能使用应用上下文。由于有许多移动的部件,你的模型是实时的,数据验证和监控需要到位,以帮助捕捉数据质量问题和模型漂移,以免它开始影响业务指标。这意味着需要将日志记录到位,工程师需要随时待命。
由于你的机器学习管道的任何元素都是批量计算的,你也无法解决现代网站和应用程序的一些最重要的用例。例如,在社交网站、新闻应用程序和大多数试图抓住和保持用户注意力的平台上,人们期待个性化的内容和馈送(甚至是下意识的),而批量计算的功能根本不允许有足够快的迭代来提供这种用户体验。欺诈检测对于大多数商业用例来说也是必须的,但这需要几乎立即识别并对不良行为者采取行动,而这在批量计算的功能中也是不可行的。
第三阶段:实时模型和特征,间隔模型训练
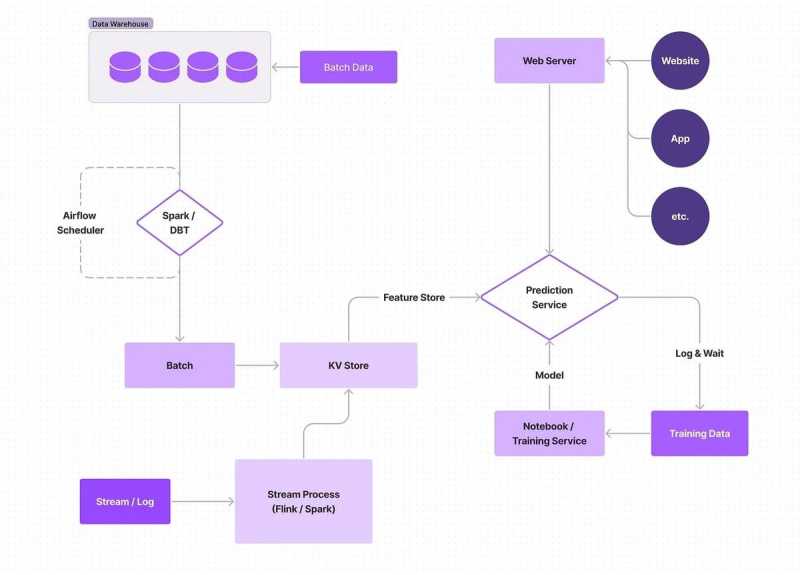
特征是实时的,而模型是实时的,并在间隔时间内进行训练。事实上,模型在使用实时更新的特征时,消除了之前阶段的大部分呆板问题。这个实现是你真正开始能够挖掘像欺诈检测这样的用例的地方,在那里你需要能够即时检测并对偏离模型预测的行为或趋势采取行动。
挑战
随着你的系统的更多部分成为实时的,更多的移动部件被引入,这增加的复杂性使你的管道更难维护。如果你从头开始构建东西,保持一个良好的SLA可能是困难的,负责不同元素的团队必须学会协调他们的努力。负责编写机器学习管道和管理功能的数据工程师需要与负责将模型投入生产的机器学习工程师协调,这些模型需要由数据科学家进行培训,所有这些人都需要同步进行;起初,这种协调需求会降低团队速度。
监测在这个阶段变得更加重要,因为你的数据变化得更快。模型最终还是会退化的,所以重要的是你要有坚实的漂移检测机制,并且在检测到漂移时有能力训练新模型。
数据更快速的变化也意味着你需要注意训练数据与服务时间的数据之间的偏差;你用来训练模型的特征与你进行预测时使用的特征看起来会略有不同。你可以使用记录和等待的方法,但这可能会使你更难试验新的特征,因为这很耗时,而且会降低你的速度。一个更准确的方法是使用时间点回填,但这很快会变得复杂。
然而,实时特征计算的另一个问题是处理坏的或失序的数据。当使用实时特征时,需要采取一些方法来处理可能不按时间顺序出现的数据,这些因素包括用户的设备在连接不畅时缓冲它发回给你的数据;在预测行为和建立让用户感到直观的工具时,用户行为的顺序往往和行为本身一样重要,而当工具感到直观时,用户会继续使用(和推荐)它们。如果你的数据被破坏,在实时特征上训练的模型也会变得不准确;这可能是一些坏的数据点的结果,或者像一个特征所使用的单位的变化没有被正确地传达给机器学习工程师。为了解决这个问题,最理想的做法是对进入系统的每个数据点进行数据正确性检查。
随着更多方面的实时性,最后一个大的挑战是,预测什么模型在实践中表现最好变得更加困难;一个新训练的模型可能在纸上看起来很好,但在生产中可能表现很差。这就是金丝雀模型发挥作用的地方;当部署一个新的模型时,你可以在最初将它应用于一小部分请求,以确保它以你期望的方式运作。然而,这也增加了你系统的复杂性。
第四阶段:实时特征和模型,在线模型训练
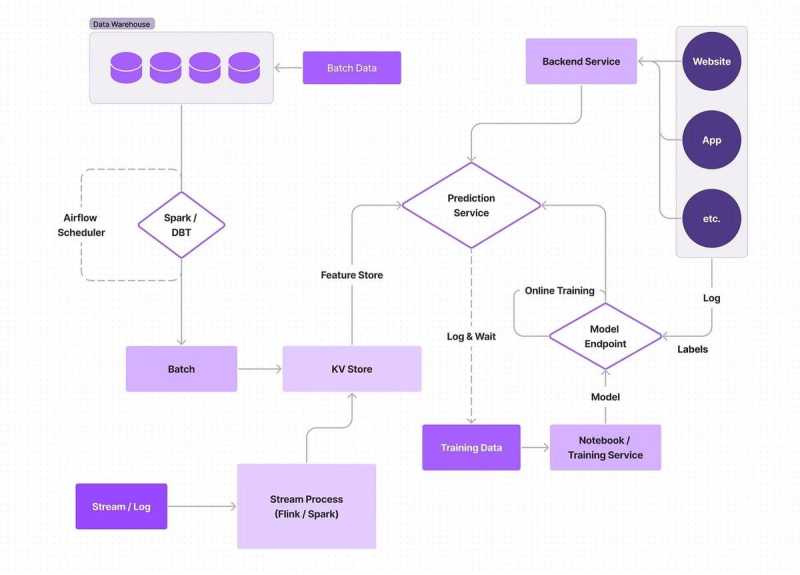
到目前为止,最昂贵、最复杂、性能最强的方法是完全实时的机器学习管道;模型实时运行,特征实时运行,模型在线训练,所以它在不断学习。由于完全实时系统所需的时间、金钱和资源是如此广泛,这种方法不常被利用,即使是FAANG类型的公司,但我们在此强调它,因为这种类型的实时实施的能力也是不可思议的。
完全实时系统最常被用于广告预测等用例,该模型预测用户参与广告的可能性;当广告是你的商业模式时,每一分钱都很重要,完全实时的机器学习管道可以确保资源被有效分配。
挑战
在线模型训练严重依赖你的模型的 "快照 "来进行检查和平衡,以及对损坏的数据作出反应的能力(基本上是你的模型的版本系统)。模型快照只要有几个坏的训练数据点就很容易变坏,导致模型行为不稳定,所以这是周期的另一个部分,你需要采用出色的监控,以及随叫随到的设置,以便快速捕捉和恢复坏的快照,并知道要恢复到哪个快照。
此外,在这种类型的系统中,前一阶段提到的许多缺点都被放大了,因为事情的发展速度成倍增加。团队必须更有效率和沟通;需要为数据质量、漂移和训练偏差增加更多更好的检查点;模型实验变得更加棘手;有更多因素需要担心确保低延迟。对于大多数公司来说,维护这种类型的系统的成本超过了它所提供的好处;如果你甚至需要质疑你是否需要在线模型训练,你可能不需要。
最后的想法
在这篇文章中,我们回顾了不同实时机器学习管道的好处和缺点。虽然任何方法似乎都有不少缺点,但最重要的是要知道这些缺点是什么,这样你就可以在它们发生之前做好准备并减轻它们,而不是在你盲目进入时争先恐后地玩打地鼠游戏。缓解这些挑战是你可以决定在内部进行的,但也有许多工具可以帮助解决每种方法所涉及的复杂问题的子集,甚至还有一些,如 芬尼爾等,可以解决大部分(如果不是全部)问题。
虽然你的用例的理想方法将取决于你的模型所依赖的数据变化的速度,但许多公司正朝着在他们的ML管道中实施更多的实时方面发展,因为这种策略带来了性能上的好处。在第三方工具的帮助下,实现一个高性能的实时机器学习管道是相对容易的,它具有实时功能和实时模型,就像阶段3那样,并获得一个完全端到端的实时机器学习管道的好处,而没有通常伴随着实时机器学习管道的基础设施的复杂性。
原文于2022年11月18日发表于 https://fennel.ai 。
大家都在看
-

专门Mac设计带数字键盘,手感接近全金属:贱驴K4Max机械键盘分享 前言:对于办公室一族,想要机械键盘的利落手感,又想有传统键盘的高效输入,带数字小键盘的机械键盘无疑是更好的选择。近期,以铝坨坨而被机械键盘爱好者喜欢的贱驴品牌,再次丰富产品体系,推出了专为苹果Mac电脑 ... 机械之最04-24
-

一步到位,最具性价比的国产豪华SUV,试驾问界M8 问界M9的市场表现不必多说,可以称神的存在,进一步下探售价且被给予厚望的”小问界M9”的问界M8是否具有M9那样统治市场的表现?带着疑问,我们来到了美丽的丽江试驾问界M8。首先这辆车虽然尺寸上比一众9系产品略小 ... 机械之最04-22
-

“我最在意的身份是教师”——追忆恩师钟秉林 【大家】作者:姜朝晖(中国教育科学研究院教育理论研究所所长)学人小传钟秉林(1951-2024),北京人。1969年至1973年,在陕西延安插队。1973年至1977年,在南京工学院(现东南大学)机械工程系学习,求学期间加入 ... 机械之最04-21
-

希捷:机械硬盘环保碾压SSD IT之家 4 月 18 日消息,Blocks and Files 研究机构 4 月 16 日公布的一份报告显示,希捷调查了基于碳排放输出的三种最受欢迎的数据存储解决方案。在固态硬盘、机械硬盘和 LTO 磁带三种存储中,机械硬盘被发现是最环 ... 机械之最04-20
-

330余家企业齐聚 “起重机械之都”河南长垣觅商机 中新网新乡4月16日电 (刘鹏 李海珠)以“数智赋能,绿动未来,质赢天下”为主题的第十届中国·长垣国际起重装备博览交易会16日在“起重机械之都”河南省长垣市开幕,来自国内外的330余家企业赴此集中展示行业新技术、 ... 机械之最04-17
-

鼓吹"机械至上"的人,真的开过现代车吗? 2024年某地车展上,一位老司机摸着新车的全液晶仪表直摇头:"现在车子整这么多屏幕有啥用?要我说还是机械仪表盘最踏实"。这话听着耳熟吗?从启动钥匙变成手机APP到机械手刹消失,总有人怀念化油器时代的"纯粹机械" ... 机械之最04-15
-

三件小事最耗气血,别再做了! 《黄帝内经》中说:“人之所有者,血与气耳。”意思是说,气血是生命的根本,如果把人体比作一台运转的机器,气血就是最根本的动力。日常生活中,哪些事情最耗气血,调补气血有哪些好方法?一起来看!(转自:首都中 ... 机械之最04-09
-

古董钟表里的机械之美,时光流转中的经典工艺。 小夜莺发现森林的钟表集体变慢,月亮像打瞌睡的老人迟迟不下班。树洞深处时间蜜蜂正用破损的蜂巢修补时针,每滴花蜜能凝固三分钟。夜莺衔来沾露的玫瑰,啄木鸟敲打水晶树校准节奏。当最后一道裂缝被晨光填平,迟到的 ... 机械之最04-09
-

"立木为信"的商鞅,为何成了帝国最锋利的刀? 公元前359年的咸阳南门,一根三丈高的木杆旁围满了看热闹的百姓。卫国人商鞅当众宣布:"谁能把这根木头搬到北门,赏十金。"人群窃窃私语却无人上前,直到赏金涨到五十金,终于有个壮汉抱着试试看的心态扛走 ... 机械之最04-09
-

机械革命最划算游戏本来了?配置低但价格给力,国补后3999元 如果说国补之后哪款笔记本能让很多人兴奋的话,机械革命极光X绝对是其中一个。如果再细分到游戏本这块,那就几乎只有这个。过气但是强大的CPU,加上主流的RTX4060或者RTX4070独显,配上合适的价格,说一机难求也不过 ... 机械之最04-09
相关文章
- 机械革命最划算游戏本来了?配置低但价格给力,国补后3999元
- 宇树机器狗最具有成长潜力的10家企业!一、长盛轴承二、绿的谐波
- 机械之舞:当国产机器人跳出《功夫》的江湖气韵
- 至今无法被超越的经典运输机安225,机械之美超级运输机!
- 一文图解 72 个机器学习基础知识点
- 在皇帝之最中,乾隆独揽了哪三项?
- 机械工程世界一流学科排名:16所进全球前30,上大北理南航闪耀!
- 40岁C罗凭什么被萨哈称为“最完美机器”?退役后必成GOAT!!
- 探寻机械设备领域的“利润巨头”
- 八下物理简单机械之杠杆知识点总结一
- 机械美学:从哈雷到凯旋,百年发动机进化史(基本知识)
- 大罗谈生涯最凶残被铲:对方鞋钉长到像穿高跟鞋,走路像机械战警
- 燕山大学的王牌专业——机械工程,中等生的不二之选
- 尼康相机创造过哪些“世界之最”?——众通社影像
- 各类轴体,75~98键,哪种机械键盘更适合你?自用百元键盘推荐
- 哪个品牌机械手表最耐用
- 机械之美,齿轮运转,动力无限!
- 标题:《探秘世界“巨无霸机械”:工业奇迹的力量与震撼》
- 学机械,这9所大学重点考虑!
- 机械仪表最好看







