To B or to C?AI大模型最直接的商业困惑
本文作者:张逸凡
编辑:申思琦
"To B(e) or not to B(e),这是问题的关键"——莎士比亚赋予哈姆雷特的名句,放在AI时代仿佛成为了一道双关。在AI大模型的商业化道路上,To B或To C的不同方式,确实事关产品的繁荣或消亡。这一问题同时影响到技术路线、研发及商业模式,对于大模型的顶级玩家可谓攸关生死。
正如《德鲁克日志》所说:"当今企业之间的竞争不是产品之间的竞争,而是商业模式之间的竞争。"在这个AI大模型商业化的关键时期,每个公司都在努力寻找属于自己的答案。
一、To C市场:潜力巨大,变现艰难
"To C是To B市场的十倍,"百川智能CEO王小川曾给出简单明了的判断。确实,相比复杂多样的To B市场,To C市场的优势显而易见:
- 庞大的潜在用户数:中国拥有12亿互联网用户,这是一个永远令人振奋的市场;
- 快速的用户增长:成功的To C产品可能在短时间内获得指数级用户扩增,以往难以想象的千万级甚至亿级日活并不遥远;
- 用户数据的马太效应:在C端的优胜者一定能取得海量的真实使用数据,凭借数据再进一步提升模型能力。
然而,To C市场也面临着巨大的挑战。用户增长容易,变现却很难。很多To C的AI公司仍在通过真金白银的投放和免费吸引用户,如何盈利很快将成为不得不回答的问题。
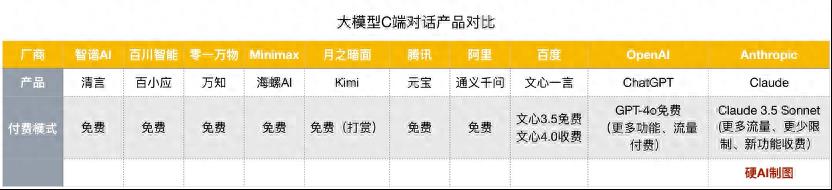
国内C端对话产品的困境
统计各大头部公司的大模型C端对话产品后,很容易发现国内市场中的顶级参赛者并不具备openAI和Claude在海外所拥有的付费号召力。而即使是后者,也在尽全力提升免费服务的范围和质量。
我们看到业界在付费问题上略有一些尝试,如Kimi的打赏功能和文心一言的仅先进版本付费,效果也不尽如人意,总体而言逊于海外市场。
一方面在烧钱投流找用户,另一方面训练模型的成本还在不断攀升。
Anthropic的CEO Dario在最近的访谈中提到,目前正在训练的模型成本超过10亿美元。他预测,到2025年,模型训练的成本会达到100亿美元,到2027年,这个数字将有可能飙升至1000亿美元。
显而易见,有效的经营性现金流入对于大模型厂商后续的天价军备赛至关重要。
竞争API调用
虽然各大模型厂商推出的C端对话式产品还没有找到合适的收入模式,但在API调用市场,已经开始产生收入。
这里值得注意的是,API市场实际上同时存在B端和C端两类用户。在当前的讨论中,B端和C端的区分并非简单地以个人或公司来划分,而是根据是否需要大模型公司提供额外的定制服务来区分。
• C端用户:不需要大模型公司提供额外定制服务的用户,使用企业提供的标准化产品,包括个人开发者和部分企业开发者。
• B端用户:需要大模型公司提供额外定制服务的企业用户。
不需要额外投入人力去满足客户的特殊需求,就意味着C端的API调用存在规模效应,用户越多越能摊薄大模型训练成本。
这种模式在传统的互联网产品中已被成功验证,随着用户数量的增多,产品开发成本不断分摊,使得产品的边际成本不断降低。
月之暗面创始人杨植麟在一次早期访谈中提到"C端模型的用户越多,边际成本越低",正是对这一趋势的洞见。
同时,C端开发者对模型的使用,可以有效带动数据飞轮的运转,显著提升大模型的能力。正如杨植麟曾说过的:“只有C端模型才有可能做到以“日”为单位的迭代速度”。
二、To B市场:关键领域的鏖战?
与海外巨头OpenAI和Anthropic在B端市场斩获颇丰相比,国内大模型厂商在B端市场的表现显得低调的多。
Sam Altman近期在内部透露,在过去六个月左右的时间里,OpenAI的年化收入增长了一倍多,达到34亿美元。从openAI的数据来看,API调用占据收入主要部分,与微软的合作贡献了2亿API调用。这一声明暗示了openAI当前在B、C端市场都游刃有余。
Anthropic CEO在近期接受挪威主权基金采访时,展现出这家业界第二的公司,目前更多地思考toB而不是toC提供服务。“我们正在考虑如何将人工智能融入工作环境。……在金融和医疗领域, Anthropic从一开始就规划了To B变现最大化的商业闭环。
企业客户不会给大模型公司带来像互联网式的爆炸增长,但可能会给公司带来稳定的现金流从而支持公司发展。特别是存在部分行业,如金融、医疗、法律和教育,对人工智能在商业环境的介入有着极高需求,获得大模型的赋能后展现出脱胎换骨的增长空间。
定制化的高成本
然而,To B市场在中国面临着独特的挑战:中国市场的B端用户需求更加繁琐,成本更高。每个企业都实现满足独特的、定制化的需求,而不是单向接受标准化的产品。
定制意味着更高的成本投入,尤其是对于场景复杂、数字化转型较晚的工作环境。
数据不完善、质量差,需要大模型公司投入更多的人力,从底层开始执行智能化设计,成本自然畸高。
更何况,一系列非技术原因,如政策要求、从业者习惯、受众取向及安全,对这一过程产生出关键影响。
这对于人员规模受限、模型持续迭代,处于激烈竞争环境中的初创大模型公司,很难成为一个特别划算的生意。对于追求回报的投资人,也不是一个性感的故事。
除了成本问题,数据资产的敏感性也构成了企业和模型厂商的隔阂。
零一万物的CEO李开复表示,AI要深度融入企业的业务流程,前提是企业愿意共享数据。
但现实情况是,国内大部分企业更注重数据隐私,在共享内部数据的行动上显得十分迟缓和被动。从保护资产角度,这样的迟疑其实不无道理。
然而,高效的信任和合作是B端大模型业务获得数据飞轮的前提。对于初创企业,与被服务的B端公司达成信任合作,需要逾越各种艰难的障碍。
即使是鼎鼎大名的Anthropic,CEO在访谈中也表示数据是公司面临的最大瓶颈,正在与其他公司努力合作解决。
先行者尝试作答——依靠开放和共享撬动B端
那么,国内大模型B端市场如何发展?
早在OpenAI的ChatGPT 3.5尚未爆发的2019年就已成立的智谱AI,与其他大模型"五小龙"发展路径略有不同。
时间差给智谱AI带来了先行机会,目前它在To B市场已取得了不少成果:
- 2023年共计中标13次,合作企业包含中国邮政储蓄银行、中核咨询、中国地质环境监测院等。
- 2000多家合作伙伴,其中有200多家企事业单位参与智谱模型共创;
智谱AI的CEO张鹏在接受采访中对B端业务曾经表达过如下两个观点:
1、包括支持API 和云端私有化部署的开放平台和本地私有化部署方案均通过多种方式确保客户隐私、数据安全与合规。
2、应对定制化高成本:智谱会努力与客户达成共识,行业能力或专业能力可以在通用基座上通过少量数据的微调和深度学习快速获得。这一过程是敏捷式的,其成果可以持续交付和优化。
也是这一代人工智能技术路线同过往的不同之处。大模型拥有较好的通用和泛化能力,微调和定制化难度与能力大幅降低。
关于toB和toC的关系,智谱也有稳健的思路。
智谱AI GLM技术团队成员曾在电话会中阐述,智谱B端和C端是相辅相成的,To B业务保证了公司基础的规模化收入,To C方面的目标是培育颠覆性的“杀手级”应用,也是公司接下来布局的重点方向。
然而,智谱AI所走的这条路径,当下其他大模型"小龙"可能并不具备复制的条件。市场环境的变化、竞争格局的演进,都使得后来者难以重复先行者的途径。
三、大模型公司的共同目标
尽管各家大模型公司在To B和To C的选择和平衡策略不尽相同,它们都有一个共同的目标:提升大模型的基础能力。
无论是通过B端的深度合作通过微调和深度学习获得行业能力,还是通过C端的广泛应用获取海量用户反馈,所有这些努力最终都是朝向更强的通用人工智能(AGI)。
然而,市场发展和竞争加剧的背景下,问题始终存在,还将持续困扰着整个行业:如何在用户增长和模型能力进步中找到可持续的经营模式?这个问题的不同答案,可能会决定各个大模型商业模式的结局。
当然,有一些预期是始终稳定可靠的。对于消费者来说,未来可能会出现更多创新的AI应用和服务;对于专业工作者,未来可以从AI智能获得更多辅助,提升更多效率。
至于投资者,则需要密切关注各家公司在商业模式、技术创新和用户增长上的突破。
结语:
To B or To C?各自做到何种程度?这个问题对于当下的大模型厂商显然没有一个标准答案。在用户增长和模型能力进步中去寻找商业化变现方式,将会是行业里每一个个体需要持续思考的问题。
本文来自华尔街见闻,欢迎下载APP查看更多
大家都在看
-

《最高明的活法:看清所有规则,为真实"饥饿"买单》 你是否曾有过这样的时刻?深夜刷着手机,对一款标价不菲的“故乡味道”预制菜心动不已。你清楚地知道,那包真空料理与童年灶台上的烟火气相距甚远。你一边嗤笑商家的情怀包装,一边默默点击付款。这看似矛盾的行为, ... 商业之最12-20
-

当下最赚的9种生意!全抓人性痛点 当下最赚的9种生意!全抓人性痛点打开手机刷购物软件,刷短视频看直播,你是不是总忍不住下单?其实不是你管不住手,而是现在的生意都精准拿捏了人性!不管是城市白领还是小镇青年,不同人群都有专属的“消费软肋” ... 商业之最12-20
-

汉阳人民集合!25万方巨型商业体,你最期待什么品牌? 汉阳的父老乡亲们,激动人心的时刻到了!我们自己的巨型商业体——金茂览秀城,全球招商已经启动啦!这意味着,我们有机会决定未来家门口能逛到什么、吃到什么!据说项目重点引入的是国际潮流品牌和沉浸式体验业态, ... 商业之最12-20
-

行业观察 摘 要恒丰银行更大的蜕变在于将金融资源向服务实体经济和国家战略倾斜:近年来,全行八成以上存量贷款投放在沿黄、京津冀、长三角、粤港澳等区域;坚持“做强本土”战略,全力服务山东“走在前、挑大梁”,承销山东 ... 商业之最12-20
-

商业合作最稳的底层逻辑:把信任检验做到位,少踩80%的坑 商业里所有“合作翻车”的闹剧,本质上都是信任的崩塌——要么是对方能力撑不起承诺,要么是人品经不住利益考验。我们总容易被饭局上的“情投意合”打动,聊几句共同观点就觉得找到了“灵魂合伙人”。但口头上的共识 ... 商业之最12-20
-

擦边主播们,把小红书变成小“黄”书 小红书正面临一场微妙的身份危机——当深V睡衣主播与"陪叔叔谈心"的标题频繁出现在推荐流,这个以女性用户为主的生活方式社区开始显露出"擦边"生态。本文深度剖析平台在用户增长与社区调性之间的博弈,揭示从7:3性别 ... 商业之最12-20
-

商业炼金术:当人性成为当代最畅销的商品 互联网时代,最好的生意不再是简单的买卖,而是一场场精准的“人性方程式”求解。一句广为流传的话道破了玄机:“向少年卖娱乐,向少妇卖仁波切,向老妇女卖青春……”但这条商业逻辑链在2025年的今天已经进化得更长 ... 商业之最12-20
-

网红直播翻车,品牌方秒切合作,背后的商业逻辑让人深思 这事儿真是来得突然,合作说黄就黄了,让人看了都觉得挺惋惜的。那家食品公司动作倒是很麻利,转眼间就把所有相关的宣传物料都给撤了个干净,生怕自己也被卷进去。企业在商言商,心里的小算盘打得噼里啪啦响——名声 ... 商业之最12-19
-

中国可回收火箭“压轴”12月 商业航天蓄力突围 2025年是中国的商业航天事业从技术积累走向爆发的一年。这一年,多型号民营航天企业完成火箭发射试验,随着卫星互联网组网加速,商业逻辑逐渐清晰,多型号新型火箭的研制节奏已全面按下快进键。同时,政策红利在这一 ... 商业之最12-19
-

管仲:从阶下囚到千古一相,如何用商业头脑成就春秋首霸? 春秋时期,齐国都城临淄的街道上,商贾云集,各国货物琳琅满目。在这繁荣景象的背后,站着一位身穿丞相官服,面容清癯的中年人——管仲。他既非出身贵族,亦非饱读诗书的儒士,却凭着一套颠覆传统治国理念的“经济战 ... 商业之最12-19
相关文章
- 中国可回收火箭“压轴”12月 商业航天蓄力突围
- 管仲:从阶下囚到千古一相,如何用商业头脑成就春秋首霸?
- 上海最富的三个区:黄浦静安徐汇,藏着怎样的房价与圈层秘密
- 中国可回收火箭“压轴”12月 商业航天迈入爆发期
- 王兴不是企业家,他是中国商业史上最清醒的「现实语法解构师」
- 怡和集团:从鸦片贸易到跨国巨擘,穿越近200年的商业浮沉
- 我的脸,是他最失败的商业并购
- 这个“少年烤鸡”用双手撬动成人世界的商业规则
- 你的欲望是否正在被商业精准收割?揭秘消费背后的“人性陷阱”
- 价格演义
- 零售额、客流同比增长超30%,在上海“最卷”商圈,这家商业体凭啥脱颖而出
- 击穿行业天花板:马斯克的万亿商业局
- 范保强:商业传奇中的“五无”标杆—解码一位企业家的责任与坚守
- 做好商业提质“必答题” 以场景之新创生活之美与增长之实
- 《道德经》被误读最深的一句话:弱者道之用,才是真正的顶级智慧
- 从6亿到24亿订单爆发!航天电子押注商业航天,散户理性布局攻略
- 《大生意人》---爽文滤镜下的商业幻梦。
- 4倍暴涨封神!牛散张素芬死磕亏损股三年埋伏挖出商业航天垄断王
- 杀疯了,大模型第一股花落谁家?
- 从10元到40元!商业航天4倍牛股背后,11家唯一龙头撑起万亿赛道
热门阅读
-
 1
世界上最小比基尼,几根绳子也能叫比基尼 07-14
1
世界上最小比基尼,几根绳子也能叫比基尼 07-14 -
 2
胡文海事件真相,以暴制暴杀了村干部等14人 07-14
2
胡文海事件真相,以暴制暴杀了村干部等14人 07-14 -
 3
好日子香烟价格,多款不同系列价格口感介绍 07-14
3
好日子香烟价格,多款不同系列价格口感介绍 07-14 -
 4
缅甸惊现最古老琥珀 距今一亿年价值连城 12-09
4
缅甸惊现最古老琥珀 距今一亿年价值连城 12-09 -
 5
5
-
 6
6
-
 7
7
-
 8
8