大模型依赖算力“大力出奇迹” 2024世界人工智能大会与会人士建议发展分布式推理降低算力成本
央广网北京7月6日消息(记者吕红桥)据中央广播电视总台经济之声《天下财经》报道,2024世界人工智能大会6日继续举行。一场分论坛重点关注的是如何降低算力成本。对大模型来说,算力越大越好,业内形象地说是“大力出奇迹”,然而,大算力意味着巨大的成本。如何在满足算力需求的情况下,降低算力成本?业内人士和专家提出了解决方案。
训练大模型,有“大力出奇迹”的说法,也就是说,算力越大,大模型可能越完善。正因如此,有测算显示,大模型训练成本70%用于算力,推理成本95%用于算力。在当前“百模大战”的背景下,要让大模型训练可持续,就必须降低算力成本。对于降成本的路径,燧原科技创始人兼首席运营官张亚林在论坛上表示,可以把大模型的推理放到边端,通过分布式推理降低算力成本。
张亚林介绍:“中国不缺应用场景、大量的端侧和边侧设备,未来端侧和边侧设备一定具有很高算力,大家看到AI PC、AI Phone已经起来。如何做分布式推理?举个例子,目前主要的手机应用都是在云端做推理。如果手机端算力能够把简单任务做了,所有省下来的成本都归手机应用公司。如果能干掉50%的推理,就能省50%的成本。所以,中国未来一定是从边侧到端侧,再到云侧的分布式推理。”
对于降低算力成本,中国工程院院士、清华大学教授郑纬民之前表示,我国现在有多个国家挂牌的算力系统,有的系统还有空余算力,这些算力也可以用来训练大模型,并且成本很低。在这场论坛上,郑纬民进一步表示,从实际尝试来看,用原有算力系统富余的算力训练大模型,成本只有原来的六分之一。
郑纬民说:“我们试了一下,把我们的一套东西加到里面。比如‘八卦炉’是10个软件,把这10个软件加到机器上。目前‘八卦炉’已经在国产算力系统中成功移植百川、LLaMA等大模型,最后结果很不错。”
降低算力成本的另一个思路是提高算力的使用效率。单个大模型训练所用的算力规模非常大,一万张算力卡组成的“万卡集群”已经成为大模型预训练的最低配置。然而在实践中,“万卡集群”的使用效率经常在50%以下,也就是说,一半以上的算力都不能发挥出来。曦智科技首席技术官孟怀宇分析,这主要是因为算力卡之间的互联,也就是“南向”互联效率太低导致的。他表示,增加“南向”互联超节点的规模,可以大幅提升算力使用效率。
孟怀宇说:“当我们从万卡集群的角度来看的时候,实际上是‘南向’的超节点规模在一定范围之内越大,GPU的利用率就越高,得到的算力会越高。这样,整个集群在卡数不增加的情况下,会得到更高的性能,也就意味着性价比更高。根据结果显示,在GPU卡数不增加的情况下,32卡的南向节点相对于8卡来说,可以获得88%的性能提升。”
数据中心与算力降成本密切相关,当前,不少数据中心并没有形成畅通的盈利模式。张亚林认为,数据中心应该改变以往的建设、运营和应用模式。
张亚林表示:“以前的模式是先建设,再找运营,找了运营再找应用。现在应该是反过来,有人来使用才算得过来账,才能去找运营。有了运营,才能够说谁来建设。这才是中国AIDC(智算中心)商业模式最关键的健康生态。其实整个商业模式非常简单,算力卡月租多少钱?能不能按照月租费用把整个投入收回来?这其实是中国在算力上需要解决的问题。”
大家都在看
-

不争之智:道德经第六十九章的现代商业启示 引言:商海中的无形兵法当你在犹疑是否要正面展开一场战争时:不论是企业弱小的企业在考虑是否要与行业龙头展开,还是面对同事的咄咄逼人是否要展开反击,《道德经》第六十九章的"吾不敢为主而为客,不敢进寸而退尺 ... 商业之最04-14
-

33.6亿!煤老板韩震出手“陕西最大奥莱”,榆林商业的煤动力 在陕北榆林,一项堪称商业地标的项目——震远奥莱丝路商贸城正式破土动工。该项目规划建筑面积达39.6万㎡,概算总投资33.6亿,一经立项便吸引了榆林全市上下的目光,刷新了“陕北商业历史之最”。而推动这一项目落地 ... 商业之最04-05
-

煤老板回家:33.6亿“最大奥莱”刷新榆林商业史 转型又有新路径!作为刷新“陕北商业历史之最”的存在,震远奥莱丝路商贸城(简称“震远奥莱”)自立项之初,就因39.6万㎡规划建筑面积、33.6亿概算总投资,备受榆林全市关注。本月17日,该项目正式破土动工。推动者 ... 商业之最04-05
-
煤老板回家:336亿“最大奥莱”刷新“榆林商业史” 转型又有新路径。作为刷新-陕北商业历史之最-的存在,震远奥莱丝路商贸城(简称-震远奥莱-)自立项之初,就因39.6万㎡规划建筑面积、33.6亿概算总投资,备受榆林全市关注。本月17日,该项目正式破土动工。推动者陕西 ... 商业之最04-05
-

范蠡:从灭国战神到商业鬼才,春秋顶流的逆袭剧本比影视剧还离谱 【灭国战神突然转行,竟是为了搞水产养殖?】公元前 473 年,姑苏城破的硝烟尚未散尽,越国上将军范蠡却做出了一个惊掉所有人下巴的决定 —— 他脱下战袍,带着西施泛舟五湖,转身投入水产养殖业。这位帮勾践完成 &# ... 商业之最04-03
-

商之大者:论商业智慧与国家命运的共生共荣 李嘉诚的商业传奇,是二十世纪华人世界最引人注目的经济现象之一。从一个贫困移民到亚洲首富,他的成功故事激励了无数创业者。然而,当我们审视这位商业巨子的财富积累过程,一个更深层的问题浮现:个人的商业智慧与 ... 商业之最04-01
-

李嘉诚的"不担心”与“最担心":一个商业帝国的经极命题 李嘉诚拄着拐杖出席长和系股东大会时,香港中环的玻璃幕墙依然折射着这座金融之都的璀璨。这位曾精准踏准香港房地产腾飞、内地改革开放、全球产业转移三大浪潮的商业巨擘,在耄耋之年的"不担心"与"最担 ... 商业之最04-01
-

李嘉诚:撕裂时代的“双面巨贾”,是商业之神还是逐利之兽 ——揭秘华人首富的财富密码与人性困局一、从难民到首富:草根逆袭的“饥饿游戏他生于战乱,15岁丧父,初中辍学,在茶楼端茶倒水谋生;他迎娶富家表妹被嘲“高攀”,却在30年间登顶华人财富金字塔——李嘉诚的故事, ... 商业之最03-31
-
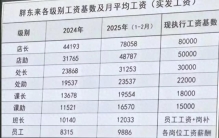
胖东来的创始人于东来:纯粹且高尚!于东来有着商业最稀缺的真诚 前言近日,一张胖东来各级别工资基数及月平均工资引发热议,员工平均工资为9886元,而工资最高的店长月薪为78058元。图片来源网络胖东来,坐落于人口大省河南,却能让员工的工资比肩一线城市,更别提令人羡慕的假期 ... 商业之最03-31
-

大武汉真的太好逛了,武汉最顶级的商业,又要连开两家…… 武汉天地应该是武汉最成功的商业了,不仅一直是武汉房价的天花板。更是凭一己之力,奠定了黄埔路到二七路的高端基因,试问武汉还有哪个开发商能做到?武汉天地也越来越好了,好消息的是光谷中心城和武昌司门口也要开 ... 商业之最03-28
相关文章
- 李嘉诚:撕裂时代的“双面巨贾”,是商业之神还是逐利之兽
- 胖东来的创始人于东来:纯粹且高尚!于东来有着商业最稀缺的真诚
- 李嘉诚的228亿美元套现:或将成为其商业生涯最昂贵的"避险"选择
- 大武汉真的太好逛了,武汉最顶级的商业,又要连开两家……
- “败者不死,只是蛰伏”——商业大佬之所以能逆风翻盘的秘诀
- 从工业锈带到商业秀场:合肥瑶海凭什么吸引K11?
- 李嘉诚:商业巨擘的多面人生
- 李嘉诚商业帝国最脏一块砖:公摊面积凭什么让中国人买单
- 太行商脉:武安商帮的五百年商业密码。太行遗珍杂志社存稿
- 胖东来:一个零售业乌托邦引发的商业地震
- 胖东来暴击商业潜规则:这个河南老六把超市开成"打工界天花板"
- 三个商业法则:胡雪岩的兴衰、现代企业的教训、穿越周期的秘诀
- 李兆基辞世!他与李嘉诚的相爱相杀,是香港商业史最精彩的篇章
- 某老板的有偿赠送真是高啊!有偿赠送:堪称现代商业最精分的发明
- 雷军的“反爽文”人生:当真诚成为最硬核的商业密码
- 印度钻石公主的豪门生存法则:一场联姻如何维系万亿商业帝国
- 原始社会顶级商人王亥,商业成功的底层逻辑
- 2024商业价值榜,赵丽颖高奢掉光,肖战王一博角逐,成毅杨紫黑马
- 老俞董宇辉"分家"真相!这才是商业江湖最高级的"相爱相杀"
- 三太陈婉珍在镁光灯下摆出的完美微笑赌王家族维系商业帝国最廉价
热门阅读
-
 1
世界上最小比基尼,几根绳子也能叫比基尼 07-14
1
世界上最小比基尼,几根绳子也能叫比基尼 07-14 -
 2
胡文海事件真相,以暴制暴杀了村干部等14人 07-14
2
胡文海事件真相,以暴制暴杀了村干部等14人 07-14 -
 3
好日子香烟价格,多款不同系列价格口感介绍 07-14
3
好日子香烟价格,多款不同系列价格口感介绍 07-14 -
 4
缅甸惊现最古老琥珀 距今一亿年价值连城 12-09
4
缅甸惊现最古老琥珀 距今一亿年价值连城 12-09 -
 5
5
-
 6
6
-
 7
7
-
 8
8