GPU时代终结?世界最大芯片加持推理狂飙20倍英伟达H100也被干趴
编辑:桃子 好困
【新智元导读】LLM若以每秒1000+token高速推理,当前最先进的GPU根本无法实现!Cerebras Inference一出世,推理速度赶超英伟达GPU,背靠自研的世界最大芯片加持。而且,还将推理价格打了下来。
LLM若想高速推理,现如今,连GPU都无法满足了?
曾造出世界最大芯片公司Cerebras,刚刚发布了全球最快的AI推理架构——Cerebras Inference。
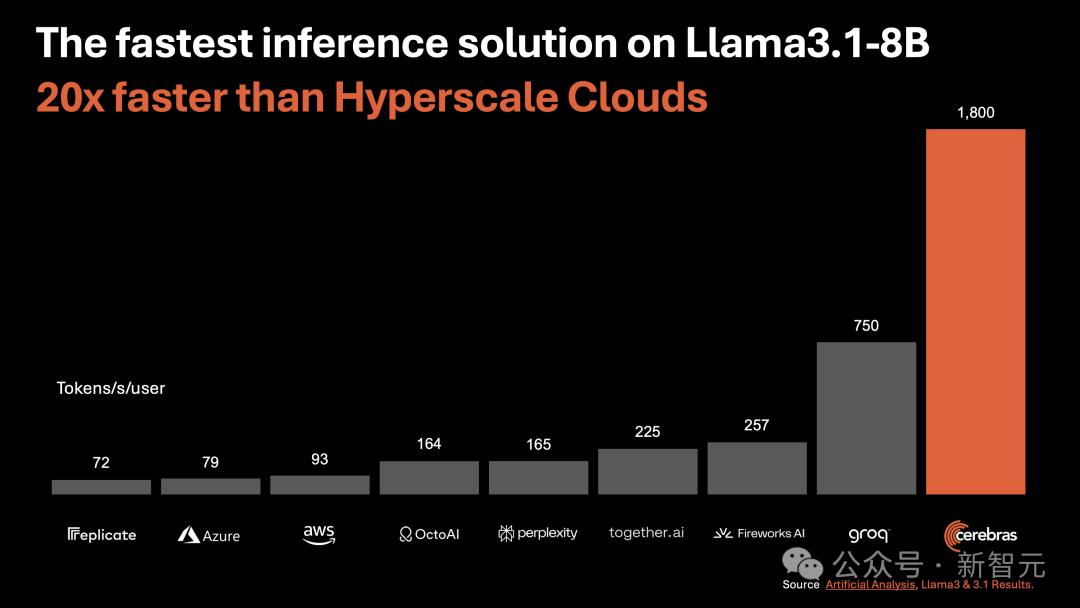
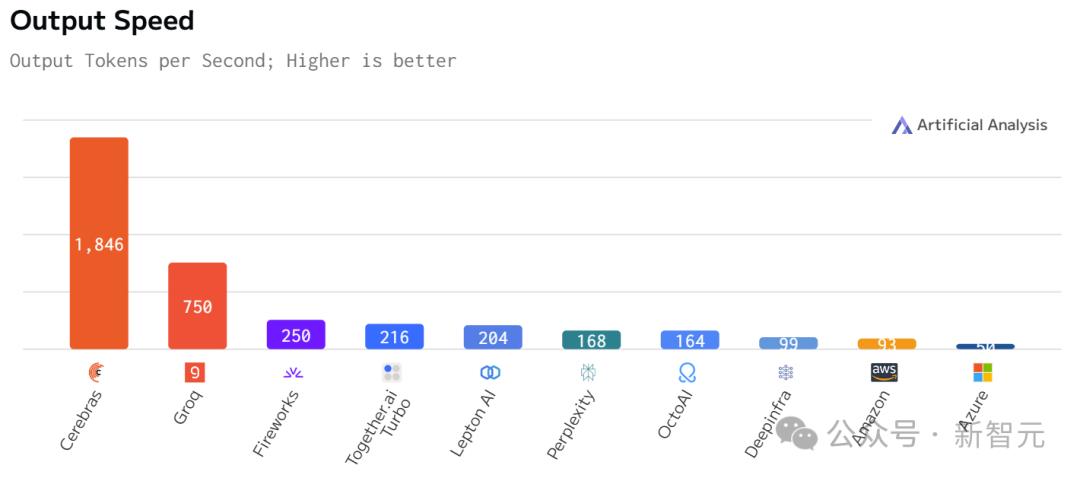
运行Llama3.1 8B时,它能以1800 token/s的速率吐出文字。
不论是总结文档,还是代码生成等任务,响应几乎一闪而过,快到让你不敢相信自己的眼睛。

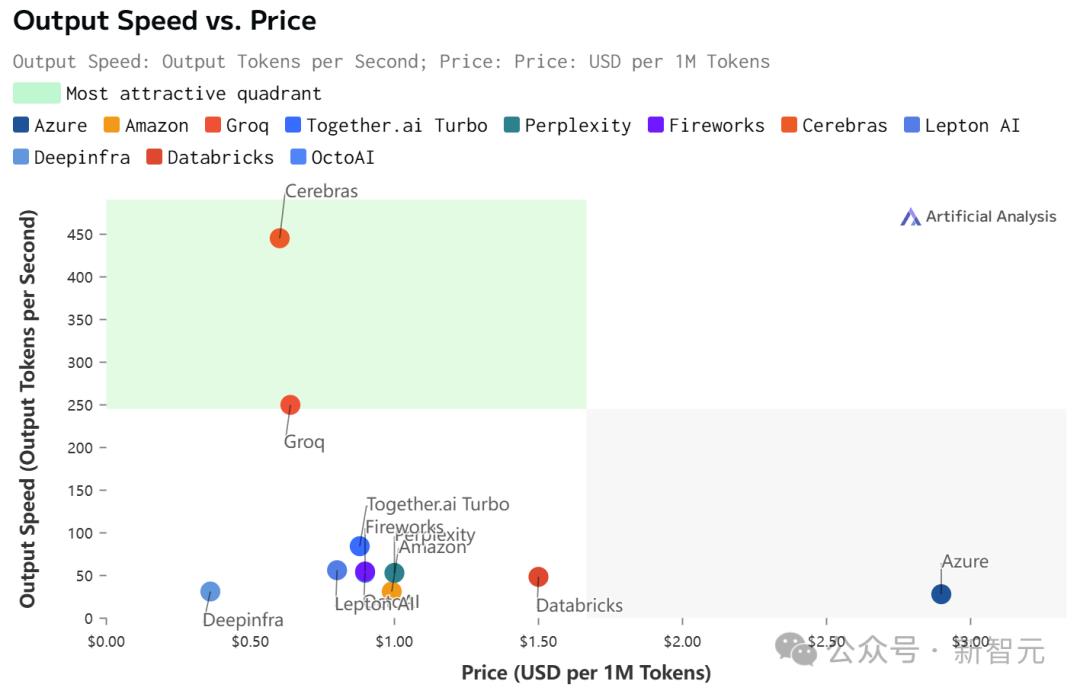
如下图右所示,以往,微调版Llama3.1 8B推理速度为90 token/s,清晰可见每行文字。
而现在,直接从90 token/s跃升到1800 token/s,相当于从拨号上网迈入了带宽时代。
左边Cerebras Inference下模型的推理速度,只能用「瞬间」、「疯狂」两字形容。
这是什么概念?
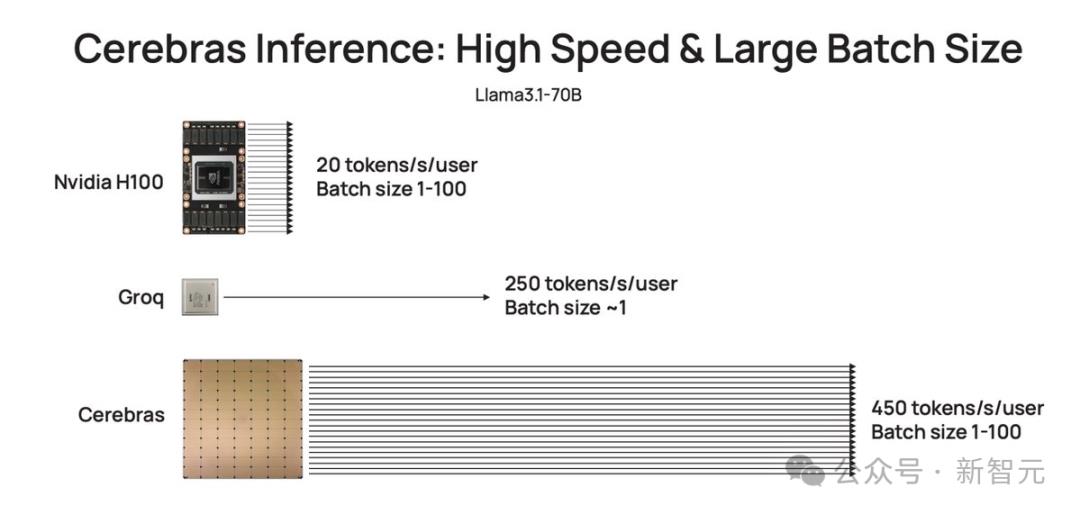
比起英伟达GPU,Cerebras Inference的推理速度快20倍,还要比专用Groq芯片还要快2.4倍。
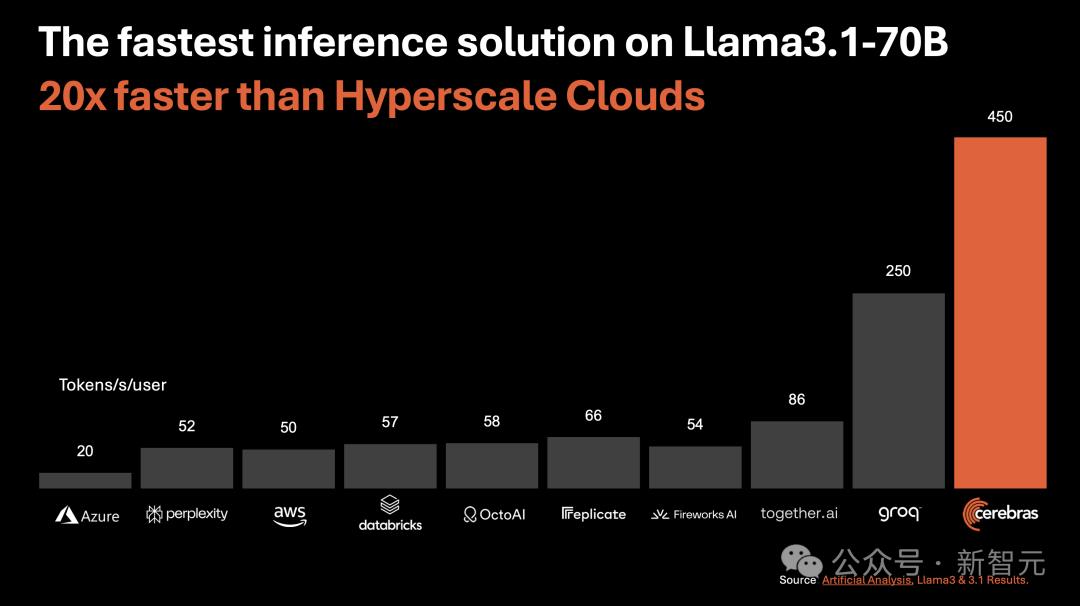
另外,对于70B参数的Llama3.1,可达到450 token/s及时响应。
值得一提的是,Cerebras并没有因为提高LLM的速度,而损失其精度。
测试中,使用的Llama3.1模型皆是采用了Meta原始16位权重,以便确保响应高精度。
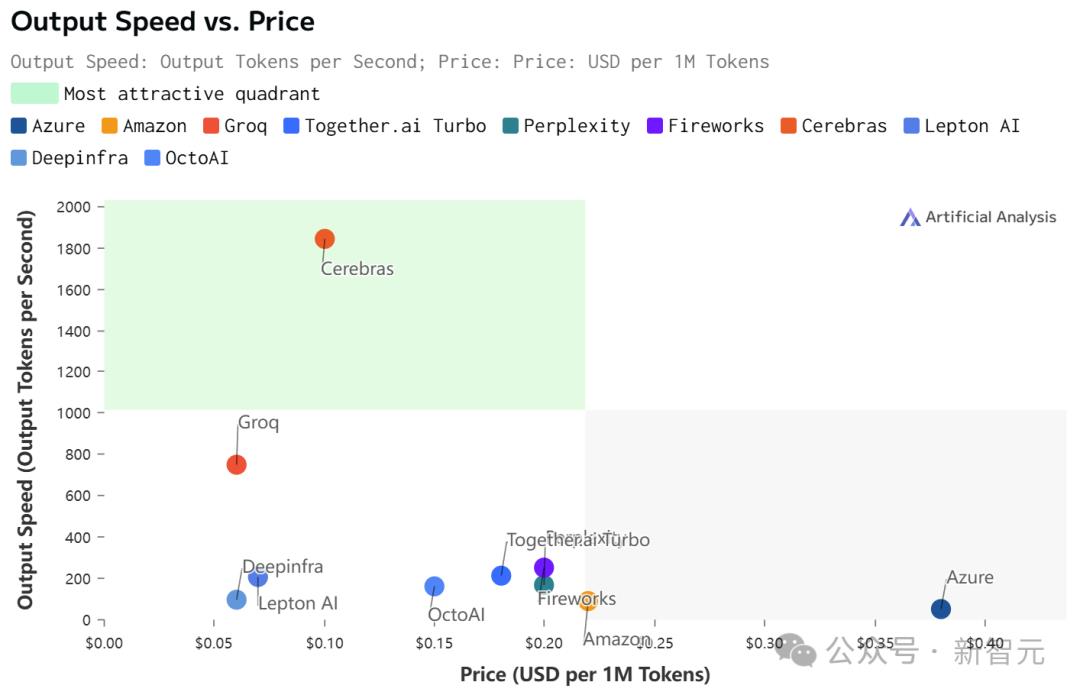
最关键的是,价格还实惠。
根据官方API定价,Llama 3.1 8B每百万token仅需10美分,Llama 3 70B每百万token仅需60美分。
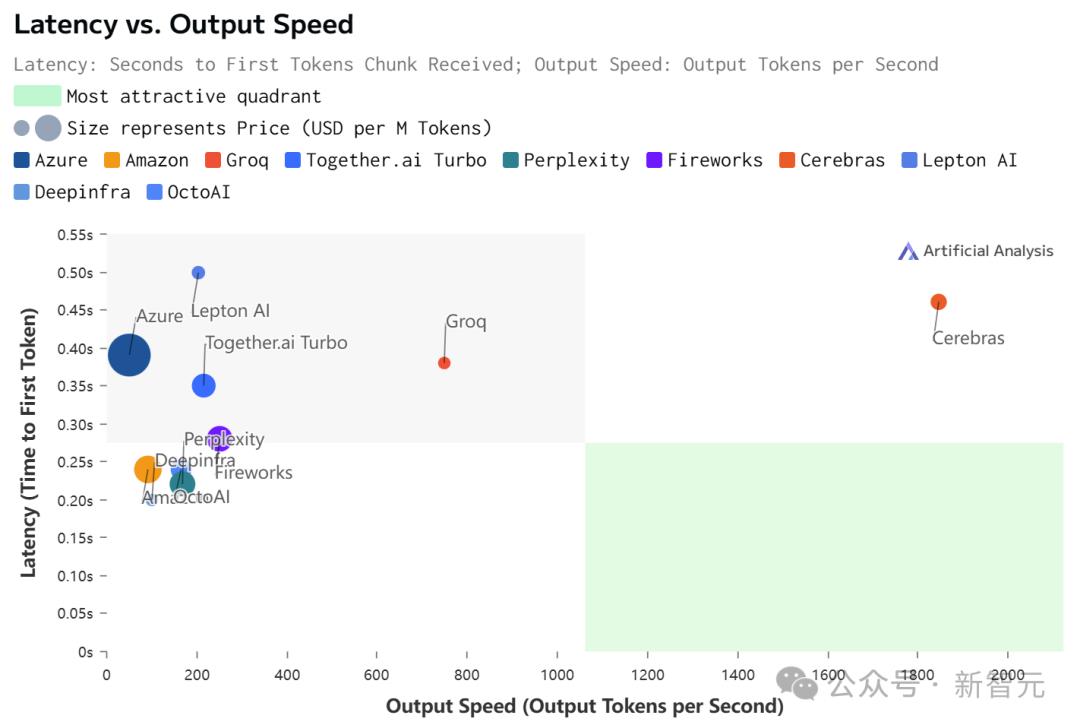
如此之高的性价比,更是打破了业界纪录——
不仅远超之前的保持者Groq,而且和其他平台相比,甚至是隔「坐标轴」相望了。
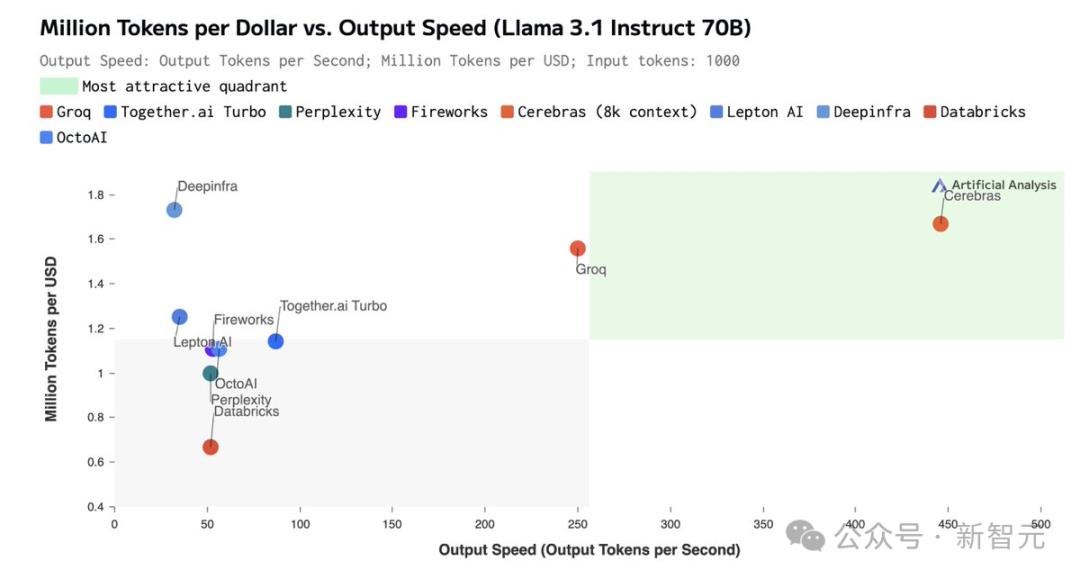
Artificial Analysis
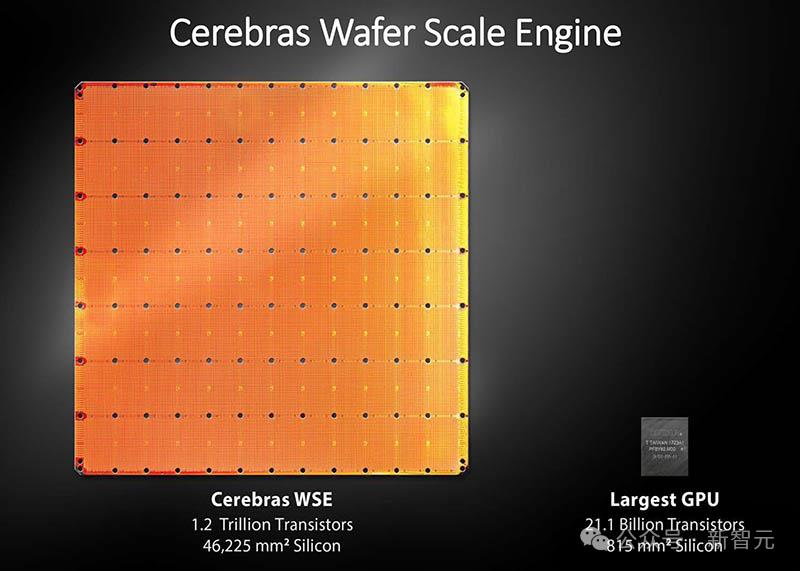
正是因为Cerebras Inference背后,是由自研的第三代芯片Wafer Scale Engine助力,才得以1/5价格快速推理Llama3.1。
看到自家模型推理如此神速,LeCun、Pytorch之父纷纷动手转发起来。


还有网友看后表示,我想要!

推理很慢,英伟达GPU也不中用?
为什么LLM的响应,就像拨号上网加载网页一样,一个字一个字慢慢地吐出?
关键原因所在,大模型自身的顺序特性,以及需要大量的GPU内存和带宽。
由于GPU的内存带宽限制,如今推理速度为每秒几十个token,而不是数千个。
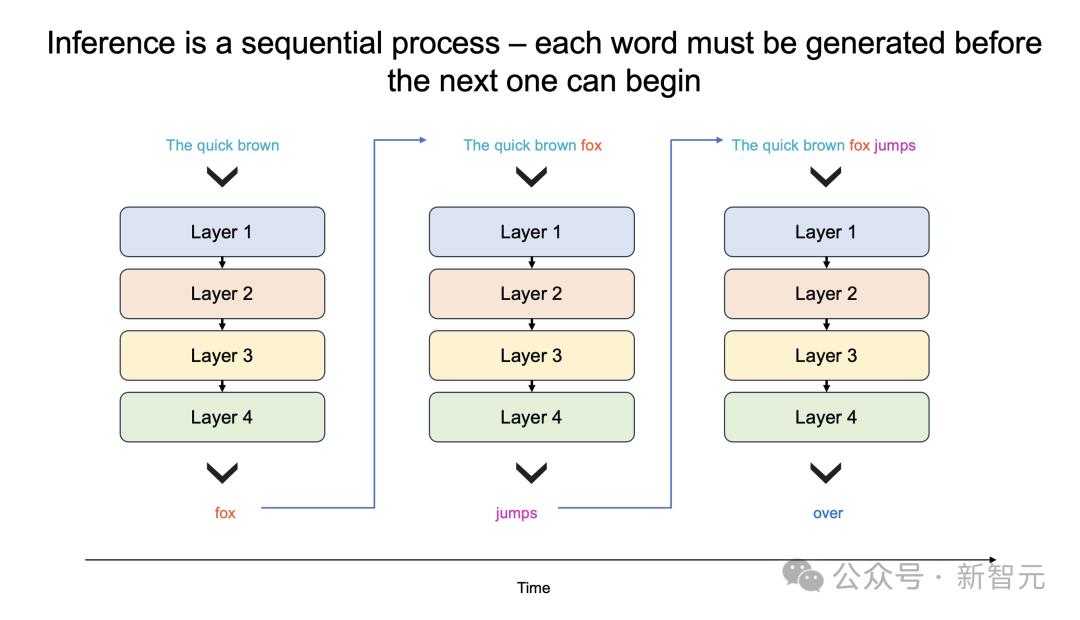
更进一步说,大模型每个生成的单词,都必须通过整个模型进行处理,即所有参数必须从内存投入到计算中。

而每生成一个单词,就需要一次处理,以此循环往复。
也就是,生成100个单词需要100次处理,因为「下一词」的预测,皆需要依赖前一个单词,而且这个过程无法并行。
那么,想要每秒生成100个单词,就需要所有模型参数,每秒投入计算100次。
由此,这对GPU内存带宽提出了高要求。
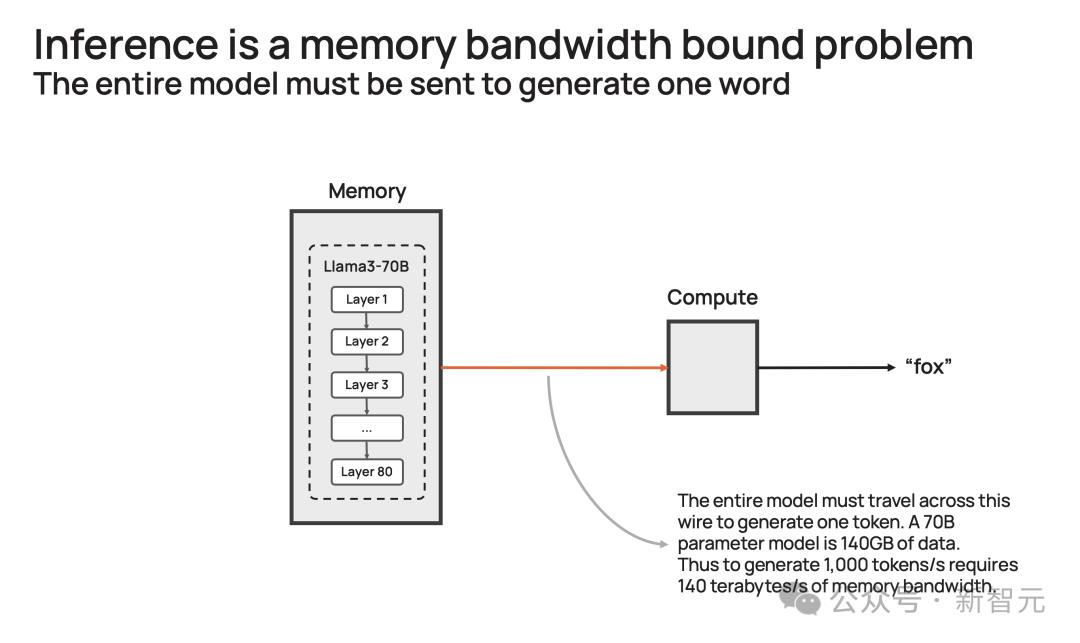
以社区流行的Llama3.1-70B模型为例。
模型有700亿参数,每个参数是16位,需要2字节的存储,那整个模型便需要140GB的内存。
想要模型输出一个token,那700亿参数必须从内存,移动到计算核心,以执行前向推理计算。
由于GPU只有约200MB的片上内存,模型无法存储在芯片。
因此,每次生成的token输出时,需将整个占用140GB内存的模型,完整传输到计算中。
再细算下来,为了实现10 token/s,则需要10*140=1.4 TB/s的内存带宽。
那么,一个H100有3.3 TB/s的内存带宽,足以支持这种缓慢的推理。
而若要实现即时推理,需要达到1000 token/s或140 TB/s,这远远超过任何GPU服务器/系统内存带宽。
或许,你想到了一种「暴力」解决方案,将多个GPU串联搭建DGX系统。
这完全是大错特错,更多的处理器只会增加系统的吞吐量(给出更长响应),并不会加速单个查询的响应时间。
自研世界最大芯片,打破推理想象
那么,Cerebras如何打破这一困局呢?
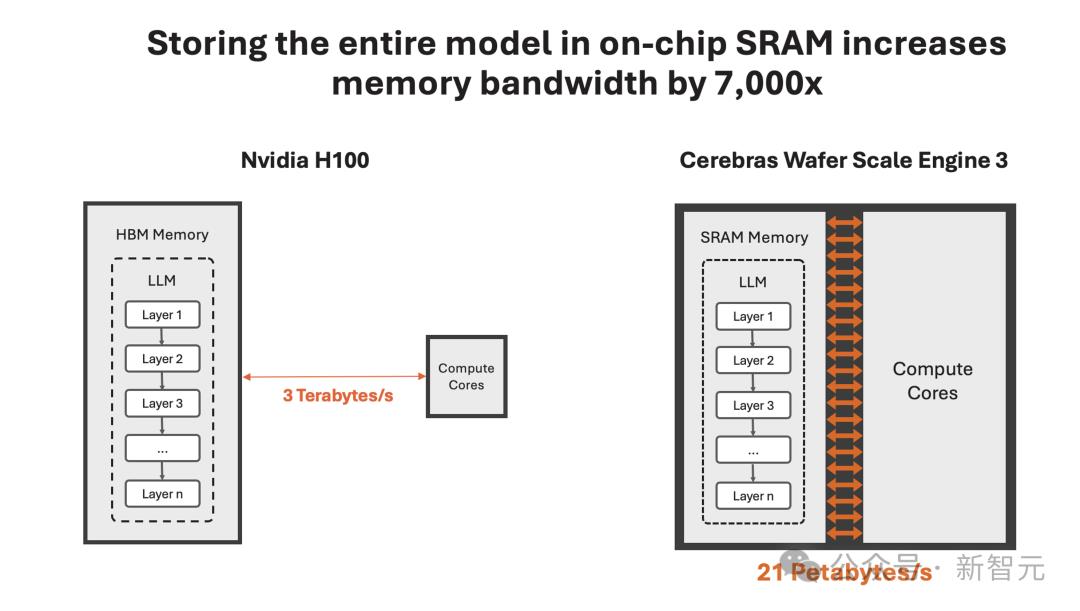
一直以来,这家公司就致力于打造世界上最大芯片,希望将整个模型存储在一个晶片上,以此来解决内存带宽瓶颈。
凭借独特的晶圆设计,WSE-3单个芯片上便集成了44GB SRAM,具备21 PB/s的内存带宽。
单个芯片拥有如此大内存,便消除了对外部内存的需求,以及将外部内存连接到计算的慢速通道。

总的来说,WSE-3的总内存带宽为21PB/s,是H100的7000倍。
它是唯一一款同时具有PB级计算和PB级内存带宽的AI芯片,使其成为高速推理的近乎理想设计。
Cerebras推理不仅速度超快,而且吞吐量巨大。
与小型AI芯片相比,芯片上内存多了约200倍,支持从1-100的批大小,使其在大规模部署时,具有极高的成本效益。
正是有了如此强大的芯片,Cerebras Inference的快速推理得以实现。
它的出现,是为了实现数十亿到万亿参数模型的推理。
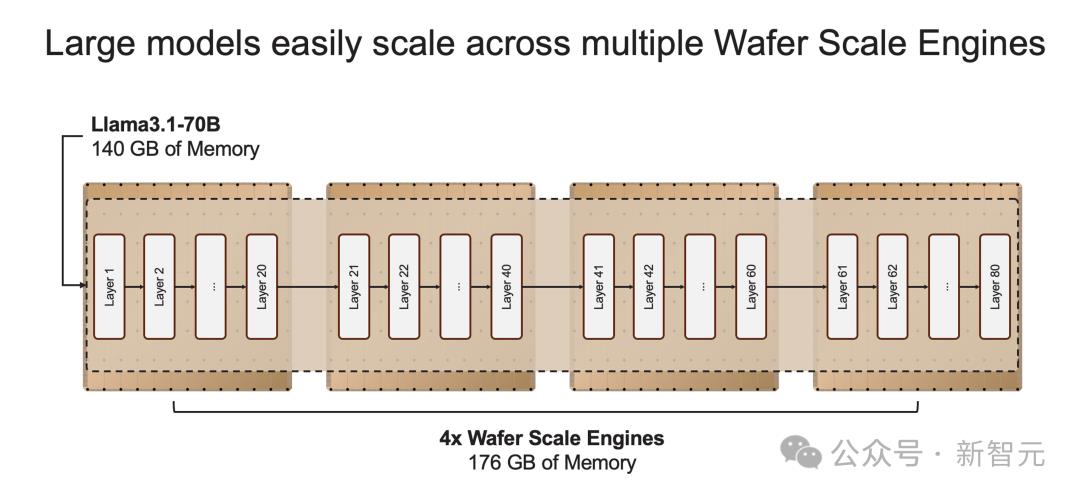
如果模型参数超过单个晶圆的内存容量时,研究人员将在「层边界」将其拆分,并映射到多个CS-3系统上。
20B模型适合单个CS-3,而70B模型则至少需要4个这样的系统。
官方表示,未来几周,将会测试更大参数版本的模型,比如Llama3-405B、Mistral Large。
16位精度,不做取舍
推理速率高,并非在模型权重上,做了取舍。
业界中,一些公司试图将模型权重精度,从16位减少到8位,来克服内存带宽的瓶颈。
这样方法,通常会造成模型精度损失,也就是响应结果的准确性、可靠性不如以前。
Cerebras Inference之所以强就强在了,速率和原始权重,皆要顾及。

正如开篇所述,他们采用了原始16位权重运行了Llama3.1 8B和70B。
通过评估,16位模型准确率比8位模型,高出多达5%。尤其是在,多轮对话、数学和推理任务中表现更好。
最优性价比,百万token免费送
目前,Cerebras Inference可通过聊天平台,以及API访问,任何一个人可随时体验。

体验传送门:https://cerebras.ai/blog/introducing-cerebras-inference-ai-at-instant-speed
基于熟悉的OpenAI Chat Completions格式,开发者只需更换API密钥即可集成强大的推理功能。

Cerebras Inference API提供最佳的性能、速度、精度和成本组合。
它是唯一能即时运行Llama3.1-70B的方案,可实现450 token/s,同样使用的是原始16位模型权重。
在此,Cerebras送上大福利,每天为开发者们提供100万个免费token。对于大规模部署,其定价只是H100云的一小部分。

首次推出时,Cerebras提供了Llama3.1 8B和70B模型,而且有能力每天为开发者和企业,提供数千亿token。
接下来几周,他们将增加对更大模型的支持,如Llama3 405B、Mistral Large 2。

有开发者问道,你们提供的rpm(每分钟请求次数)和tpm(每分钟处理token数)是多少?
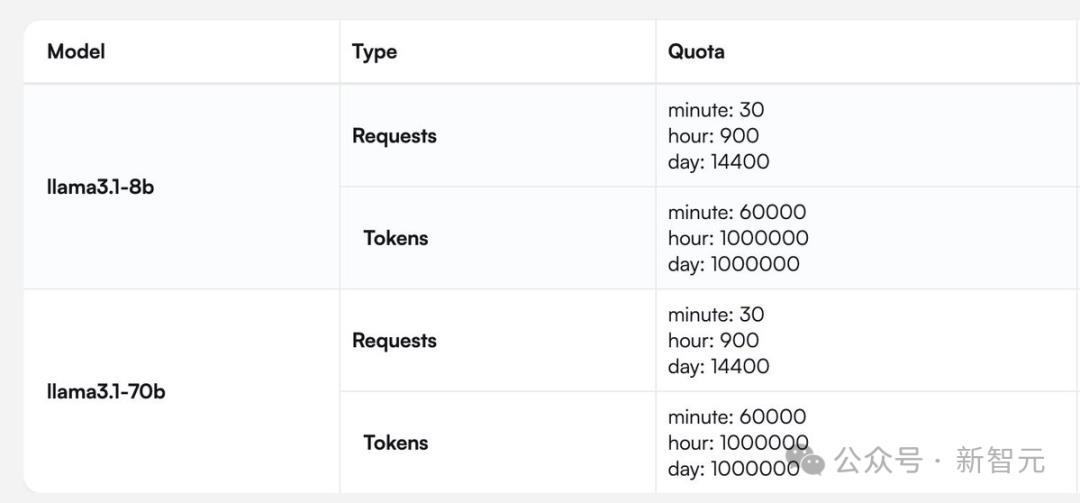
Cerebras提供了一张针对Llama 3.1 8B和70B模型完整的请求/token处理数的图。
快速推理,不只为速度
最后,让我们来聊聊,为什么快速推理非常重要?
通常,LLM会即刻输出自己的全部想法,而不考虑最佳答案。而诸如scaffolding(脚手架)这类的新技术,则如同一个深思熟虑的智能体,会在作出决定前探索不同的可能解决方案。
这种「先思考后发言」的方式在代码生成等严苛任务中,可以带来超过10倍的性能提升,从根本上提升了AI模型的智能,且无需额外训练。
但这些技术在运行时,需要多达100倍的token。
因此可见,如果我们能大幅缩短处理时间,那么就可以实现更为复杂的AI工作流程,进而实时增强LLM的智能。
速度爆表,但上下文只有8K
虽然在价格和延迟上,Cerebras都不是最低的。
但极致的速度,确实为Cerebras带来了极致的速度-价格和速度-延迟比。
不过,值得注意的是,在Cerebras上跑的Llama 3.1,上下文只有8k……
相比之下,其他平台都是128K。
具体数据如下:
Llama 3.1 70B
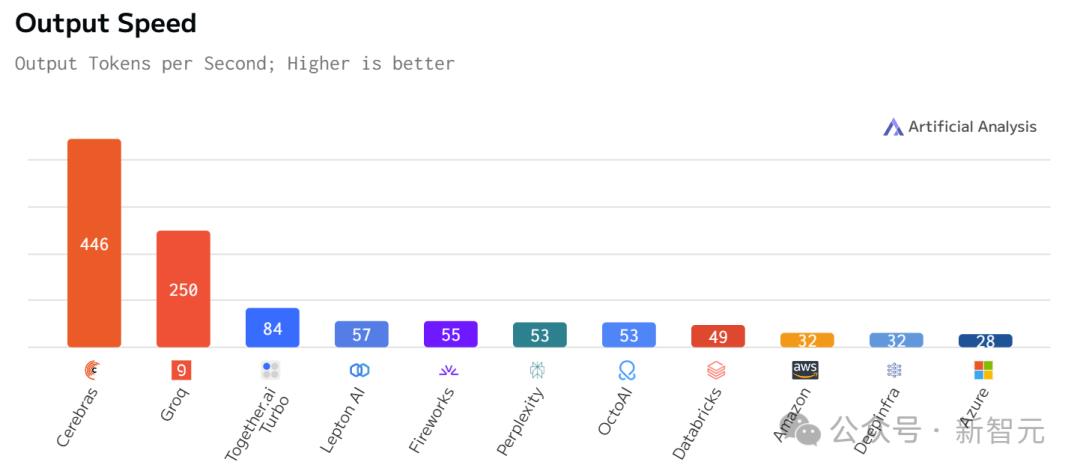
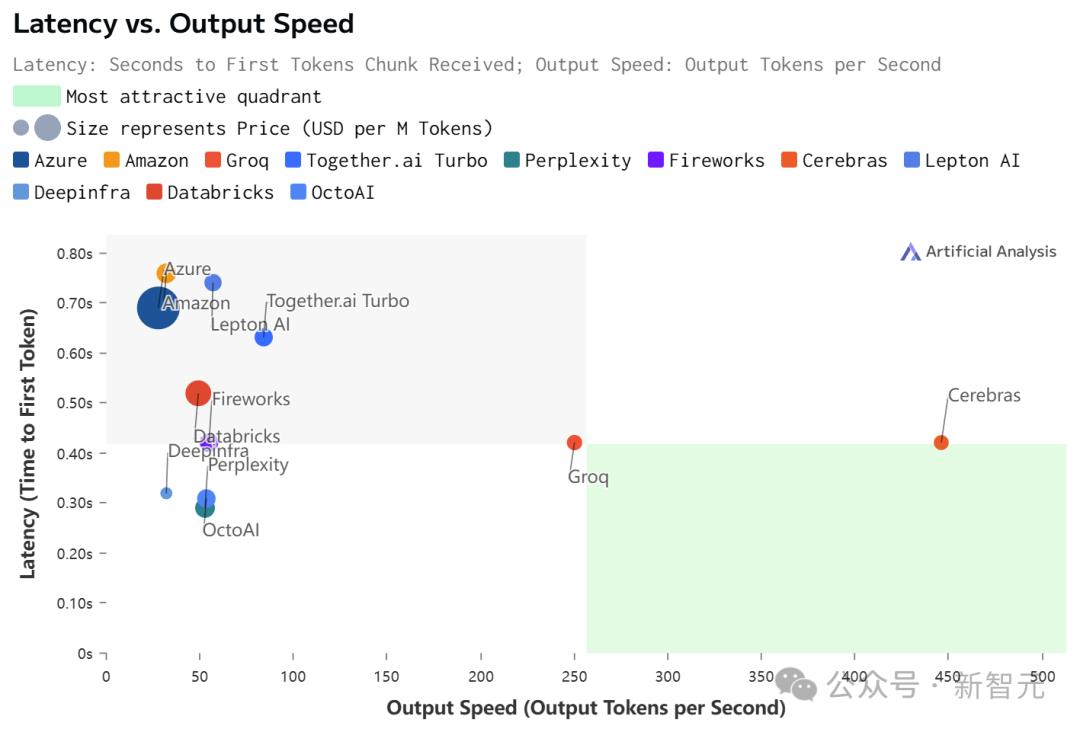
Llama 3.1 8B
参考资料:
https://cerebras.ai/blog/introducing-cerebras-inference-ai-at-instant-speed
https://x.com/CerebrasSystems/status/1828464491677524311
https://artificialanalysis.ai/models/llama-3-1-instruct-70b/providers
大家都在看
-

全球十大“天价龙虾”,龙虾中的“爱马仕”!一口龙虾一口金! 一口龙虾一口金,这些海洋龙虾珍品堪称:龙虾中的“爱马仕”!在高端海鲜的世界里,龙虾一直是奢华与地位的象征。宴席上被视为定位价格高低,菜式软硬的标尺。但您可能不知道,在龙虾家族中,有些品种的价格堪比一辆 ... 世界最大12-20
-

全球最大级CABU船顺利靠泊福州港 12月15日,挪威籍超大型CABU船“芭乐”轮顺利靠泊福州江阴港区13A泊位,这是超大型CABU船首次靠泊福州港,既有效满足了万华码头年终物资运输需求,也彰显了福州港对接大型船舶、服务重点物资运输的能力提升。CABU( ... 世界最大12-19
-

尽力而为,量力而行 时间,是一个人的本能,能拿到就得去做值得的事,干净的路,选择的门,捍卫自己的价值,人的一生,总要坚持很多选择,为自己选择路程。时间的绊脚石,总为人伤感很多,学会提要求,学会放下,看懂世事,坚持的岁月, ... 世界最大12-18
-

全球最大!首靠福州港! 15日随着挪威籍超大型CABU船(氢氧化钠/散货船)“芭乐”轮成功靠泊福州港江阴港区13A泊位标志着福州港正式具备接卸全球顶级氯碱运输船舶的能力为福建氯碱产品走向国际打通关键物流通道本次靠泊福州港的“芭乐”轮总 ... 世界最大12-18
-

世界最大直径高铁盾构机“领航号”掘进突破万米大关 12月16日,由我国自主研制的世界最大直径高铁盾构机——崇太长江隧道“领航号”掘进突破10000米大关,距离长江南岸仅剩1000米,标志着崇太长江隧道工程向着打通“最后一公里”、实现350公里时速高铁过江的目标,迈出 ... 世界最大12-17
-

我国自研世界最大直径高铁盾构机掘进突破万米大关 12月16日,在万里长江的入海口,由我国自主研制的世界最大直径高铁盾构机——崇太长江隧道“领航号”掘进突破10000米大关,距离长江南岸2号井仅剩1.3千米,标志着崇太长江隧道工程向着打通“最后一公里”、实现350公 ... 世界最大12-17
-

世界最大直径高铁盾构机“领航号”在长江入海口掘进突破万米 中新网上海12月16日电 (殷立勤 许文峰)12月16日,在万里长江入海口,中国自主研制的世界最大直径高铁盾构机——崇太长江隧道“领航号”掘进突破10000米大关,距离长江南岸仅剩1000米,标志着这一世界级越江隧道工程 ... 世界最大12-17
-
2025全球十大强国揭晓:美国依旧称霸,中国凭何稳坐第二? 强国这个词,听起来很宏大,但其实它真切地塑造着我们每个人的生活境遇——从就业机会、物价水平到所能触及的科技与文化。一份由《美国新闻》发布的2025年全球十大强国榜单,或许不能定义一切,却为我们观察世界格局 ... 世界最大12-16
-

强大,是从沉默开始的 挣钱的本质是生存,一个人选择做自己,就得学会看别人,在对的路上选择,在事的抉择上选择自己,每一次稳重,都是对自己的尊重。时间的筹码,给自己加注,学会看,看自己的价值, 学会问,问别人的本质,思维的运作 ... 世界最大12-15
-

全球最大冰淇淋公司上市,对中国市场影响几何?丨消费参考 21世纪经济报道记者贺泓源、实习生李音桦全球最大冰淇淋公司梦龙如期上市。12月8日,该公司正式开始在阿姆斯特丹泛欧交易所、伦敦证券交易所和纽约证券交易所三地上市交易。从联合利华分拆后,梦龙成为独立冰淇淋巨 ... 世界最大12-13
相关文章
- 全球最大冰淇淋公司上市,对中国市场影响几何?丨消费参考
- 创下五大世界纪录,向全行业开放共享!全球最大的吉利全球全域安全中心正式发布
- 美媒猛夸055是“超级驱逐舰”,全球最大火力最强!但055B更强
- 全球最大!就在珠海这里
- 世界最大!大连制造!
- 打破80年纪录!战败国先开建,问鼎全球最大驱逐舰,中国路在何方
- “张一鸣是全球最大毒枭?”自媒体被判败诉,被强制执行5万元!
- 10万亿!马斯克要干出全球最大IPO了?
- 世界最大跨径四主缆悬索桥全线贯通
- 全球最大冰淇淋公司上市
- 世界最大!毒气洞穴惊现100平方米蜘蛛网,里面藏着10万只蜘蛛
- “世界最大蝙蝠”已在广州安家,即日起面向公众展出
- 世界上最大的10个女人
- 安德烈·贝斯特里茨基:中国有世界最大规模的中产阶层丨读懂中国
- 重18000吨,差点成为世界上最大的火箭,海里也能发射火箭吗?
- 世界最大,完成吊装
- 世界最大、全球首创、填补全球空白!我国在这一领域实现重要突破
- 杀死世界上最大的生命,我们用了八天
- 世界最大!沙特萨勒曼国王公园最新施工进展
- 世界上最大的蛇到底有多大呢?秦岭真的有盘山巨蟒吗?
热门阅读
-
 1
1
-
 2
泷泽萝拉作品,光看一眼就让人欲罢不能 07-14
2
泷泽萝拉作品,光看一眼就让人欲罢不能 07-14 -
 3
高岗事件真相令人震惊 究竟有何隐秘内幕 07-14
3
高岗事件真相令人震惊 究竟有何隐秘内幕 07-14 -
 4
北京大裤衩 也就是中央电视台总部大楼 10-24
4
北京大裤衩 也就是中央电视台总部大楼 10-24 -
 5
江户四十八手 看一看可以年轻十岁 11-01
5
江户四十八手 看一看可以年轻十岁 11-01 -
 6
柳州莫菁视频流出,最终判定是男友所为触及法律底线 11-14
6
柳州莫菁视频流出,最终判定是男友所为触及法律底线 11-14 -
 7
揭秘翁帆怀孕真相 杨振宁和翁帆的孩子 11-15
7
揭秘翁帆怀孕真相 杨振宁和翁帆的孩子 11-15 -
 8
世界上最大的火车站,在中国(100个足球场大) 05-26
8
世界上最大的火车站,在中国(100个足球场大) 05-26