比GPT-4快18倍,世界最快大模型Groq快速证伪?

今天讨论了一天的groq,结论就是同样完成LLaMA 70b 模型推理,采用 int8 量化,运行三年的话,Groq 需要的硬件采购成本是576卡1144 万美元,运营成本是 76.2 万美元或更高。H100的硬件采购成本是 8卡30 万美元,运营成本是 7.2 万美元或略低。
为什么需要576张,有海外大神专门算过,另一位技术大牛也做了类似的计算,groq没有显存仅仅靠SOC SRAM,假设有230MB的SRAM , 运行一个INT8的 llama-70B=70GB/0.23GB = 305张卡,考虑到SRAM利用率等各种问题,预计需要320张卡,每个服务器智能插入8张卡,分摊成本每张卡不低于2500$(卡0元计算),也就是服务器40台+交换机, 大概150万美元可以运行llama-70B。如果换成A100的8卡,大概INT8能够做到100token/s.,也就是120万人民币投入。
结论就是,Groq看起来效果惊人,但一算TCO,根本不具有经济性...那个效果吓人的视频,揣测下,是不计成本的堆卡堆出来的。诚然这个架构有其特点,比如NV大佬提到的针对bs1做了优化,的确在小batch size尤其是bs1显示出了优势,但可能也就在小模型、本地或者线上定制化推理服务能有限场景,一旦到了云端大规模集群推理,就不可用了,尤其是GPU或者大厂ASIC被充分优化、且利用率又比较高的场景。
这个路子是否成立都是个问号,groq还有个前辈graphcoe,其sram是groq的2.5倍,现在公司生意都快没了(除了前两天融资)...最致命的问题是,这种架构仅存只有SRAM(没错,这是短板...先不管你股票咋炒的)。
目前的计算架构存储层级是这样的,register file->SRAM->HBM->DDR->NAND->不常用的数据还可以offload到Disk,从左到右速度和和带宽都在降低,比如access SRAM 带宽认为约等于无限 一次ACCESS 2ns delay (先进工艺下),Acess HBM可能是几个micro second,Access NAND是milli second量级。但从左到右单bit的成本在依次降低。
说白了,最左边,无限快,但你用不起,往右边,贼便宜,但不够快。而目前LLM大家天天念叨的内存墙瓶颈,尤其是推理只做一次前向计算所有的参数要遍历一遍,因此需要
1)存的足够大;
2)读取也要足够快。
结论:LLM需要的存储要在成本可控的前提下,在速度和容量之间做一个折中和平衡。因此才有了HBM的大规模应用,这是产业的选择(最早是AMD),综合考虑了量产难度、成本、速度、工程实现性等等。下一步最多如大家讨论的HBM4与逻辑堆叠或者chiplet,但你说换掉HBM?步子迈太大了...不管存内计算近存计算存内处理,一旦到了工程实现性、良率就不吱声,再考虑经济性就歇菜。

我会在 公众号:海涵财经 每天更新最新的华为概念、创新减肥药、数字经济、ChatGPT、AI算力、CPO/硅光芯片、大数据、6G卫星、数据要素、医疗新基建、一体化压铸、 汽车智能化,激光雷达,HUD,车规芯片,空气悬挂、L3级智能驾驶、PET铜箔,纳电池,800V高压,光伏HJT、TOPCON、钙钛矿、光伏XBC、BIPV、IGBT芯片、碳化硅SIC、CTP/CTC/CTB电池、4680电池、工业母机、海风柔直高压、新能源车高压快充、高镍三元、碳纤维、PET铝箔、PET铜箔、空气源热泵、新材料、中药创新药、中药配方颗粒、乡村振兴、锂矿、钒液流电池、钠离子电池、分布式储能、集中式储能、抗原检测等最新题材热点挖掘,未来属于高预期差的结构性市场,把握核心赛道以及个股的内在价值逻辑预期差才是根本所在。
— END —
先赞后看,养成习惯
免责声明:图片、数据来源于网络,转载仅用做交流学习,如有版权问题请联系作者删除
大家都在看
-

“全球最快高铁”如何炼成 本报记者 李迅典正在试验中的CR450动车组 (铁科院铁道科技影视中心摄影)跑出单列时速453公里、相对交会时速896公里最新纪录的CR450动车组,正在进行运营前的“毕业考试”——60万公里运用考核。这款被视为“十四五 ... 世界最快12-06
-

“全球最快高铁”要来了! 被称作“全球最快高铁”的CR450动车组正在沪渝蓉高铁开展运用考核2021年,“十四五”规划102项重大项目之一的CR450科技创新工程启动。去年年底,CR450动车组样车发布,目前已完成在不同速度、不同场景中的多项试验。 ... 世界最快10-22
-
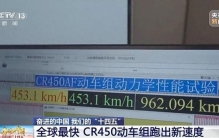
“全球最快高铁”,有新消息! 被称作“全球最快高铁”的CR450动车组样车去年底公布后,目前正在不同速度、不同场景中进行多项试验。试验期间,CR450动车组跑出了动车组单列时速453公里、相对交会时速896公里的最新纪录。目前,CR450动车组正在沪 ... 世界最快10-22
-
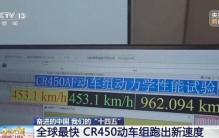
全球最快动车组,正在“刷里程” 人享其行、物畅其流是我国交通运输业发展的目标。“十四五”期间,我国加速织就交通“经纬网”,已拥有世界最大的高速铁路网、高速公路网和邮政快递网,综合立体交通网总里程已超过600万公里。目前,我国国家综合立 ... 世界最快10-21
-

“全球最快高铁”,有新消息 被称作“全球最快高铁”的CR450动车组样车去年底公布后,目前正在不同速度、不同场景中进行多项试验。试验期间,CR450动车组跑出了动车组单列时速453公里、相对交会时速896公里的最新纪录。目前,CR450动车组正在沪 ... 世界最快10-21
-

时速453公里!“全球最快高铁”正在刷里程,明年全面测试!上海到北京2.5小时? 据央视新闻最新消息:被称作“全球最快高铁”的CR450动车组正在沪渝蓉高铁开展运用考核2021年,“十四五”规划102项重大项目之一的CR450科技创新工程启动,去年年底,CR450动车组样车发布,目前已完成在不同速度、不 ... 世界最快10-21
-

全球最快高铁,有重要进展! 被称作“全球最快高铁”的CR450动车组,已完成在不同速度、不同场景中的多项试验,试验期间,更是跑出了单列时速453公里、相对交会时速896公里的最新纪录。目前,CR450动车组正在沪渝蓉高铁开展运用考核,什么是运用 ... 世界最快10-21
-

“全球最快高铁”,要来了! 被称作“全球最快高铁”的CR450动车组样车去年底公布后,目前正在不同速度、不同场景中进行多项试验。试验期间,CR450动车组跑出了动车组单列时速453公里、相对交会时速896公里的最新纪录。目前,CR450动车组正在沪 ... 世界最快10-21
-

世界最快人力自行车,人躺在里面就能骑,时速高达144公里! 注意看,这难道是一颗"蛋"冲过去了吗?此时它正在公路上快速的飞驰着,镜头拉近一看才知道,实则它是世界上跑的最快的人力自行车。令人感到惊讶的是,它的时速竟然超过了144公里,简直把家用汽车远远的甩在 ... 世界最快10-14
-

关键核心技术全面自主化!我国首列,全球最快! 科技日报记者 宋迎迎9月18日,具有完全自主知识产权的我国首列中国标准智能市域列车在青岛亮相,标志着我国在市域轨道交通装备领域取得重要新突破,系列化中国标准智能市域列车实现示范应用。它的问世,引领我国市域 ... 世界最快09-20
相关文章
- 世界最快人力自行车,人躺在里面就能骑,时速高达144公里!
- 关键核心技术全面自主化!我国首列,全球最快!
- 全球最快!时速400公里高铁列车来了
- 全球最快列车亮相“高铁创新之旅”
- 全球最快!在武汉!
- 全球最快、跑出全新试验速度 中国高铁再次冲上热搜
- 再出手!全球最快高铁成功试跑,北京到上海仅需2.5小时?
- 特稿丨时速400公里!全球最快,惊艳亮相!
- 时速400公里运营!“世界最快高铁”将在成渝间开跑
- 时速400公里!全球最快,惊艳亮相!
- 全球跑得最快的高铁,内部长啥样?一探究竟→
- 亮个相吧,全球跑得最快的高铁!
- 时速400公里!全球最快高铁来了
- 时速650公里!全球最快!
- 全球最快!CR450动车组样车在北京发布
- 10米/秒!全球最快的机器狗正式亮相
- 世界最快中低速磁浮开工建设
- 全球公认最快的燃脂运动,每天20分钟,一周暴瘦一圈!
- 世界上“倒退”最快的国家:从发达国家到一贫如洗,只用5年时间
- 全球最快致死记录之一,79年男孩被太攀蛇咬一口,10分钟人就
热门阅读
-
 1
1
-
 2
2
-
 3
3
-
 4
世界上最快的手指,一秒钟敲击琴键13次 10-12
4
世界上最快的手指,一秒钟敲击琴键13次 10-12 -
 5
世界上速度最快的火箭车,每小时达到1600公里 04-26
5
世界上速度最快的火箭车,每小时达到1600公里 04-26 -
 6
6
-
 7
世界上飞行最快的鸟,灵活的军舰鸟 04-26
7
世界上飞行最快的鸟,灵活的军舰鸟 04-26 -
 8
8